
Encounters with Maestro and Wrangler
A few days ago, I came across the short preview of an analytics software from Tableau that is called Maestro. This software – which is being called project by Tableau as it is supposed to become part of the tableau software products – is focussing on preparing data before the analyst is analyzing the data. Preparing data starts with importing data from one or more data sources and combining them via different set operations. Traditionally this is done via textual commands (e.g. written in SQL, MDX), whereas in Maestro it is done via a graphical interface which is visualising data sources, the ways they are combined and the transformations the user is applying to the data. This interface is presented in a pane which is called the „Flow“ and it reminds me of the visualisation of data operations in the Trifacta Wrangler which is focussing completely on the data preparation phase for data analysts.
There are even more parallels between Project Maestro and Trifacta. A large part of work before an analyst starts the analysis itself, he needs to invest into exploring the technical nature of his data and clean them up. Real world data are messy: columns having the wrong data type, data are missing, same things written in different ways, and so on. Everyone working with data knows that much time is invested into this kind of work. Smart analytics software like Maestro and Wrangler are supporting the user in multiple ways. Some examples are assistive technologies like:
- automatically analysing imported data and categorizing, structuring it and displaying the data type
- profiling the data values and showing the distribution of current values in a histogramm, so that the user can discover missing, mismatching or inconsistent values more quickly.
I have discussed some of those features in analytics software in more depth in the article „Von der Tabellenkalkulation zur assistenzgestützten visuellen Analyse“ for the book „Qualität und Data Science in der Marktforschung“. In my article I identify important changes in interface paradigms of Business Intelligence software from an Interaction and UX Designers point of view.
From Tabular Calculation to Assistent-supported Visual Analytics
Written in summer 2017, the article shows and explains that interfaces not only of BI software but of data analytics software in general are changing towards:
- deep and more intelligent usage of visualisation of data in all phases of the analysis
- integration of assistive technologies and libraries using artificial intelligence and machine learning
- Interface design making use of state-of-the-art visual and interaction design principles
Both Trifacta Wrangler and Project Maestro are part of an overall change in the way, user interfaces for analytics software are designed. And these changes are connected with changes in the type of user who is using these kind of tools. Previously the user types Data Analyst and Technical Architect have been the almost exclusive user of Analytic tools and handed over the results to the information consumer.
Nowadays, the information consumer has evolved into the new user type of information prosumer, as I call him along the lines of Tofflers „prosumer“ definition. An information prosumer is a person who is analysing data on his own, navigating through all the available data, exploring the data ad-hoc, and adapting information depth and width of his dashboard to his current and individual needs, without having been trained in expert tools for data retrival, ETL, BI, architecture of data warehouses and the like. Keywords connected with this already emerged type of user are „democratisation of data“ and „citizen data scientist“.
In my above mentioned article I discuss in depth why this user type matters a lot to software engineers, UX designers and product owners and what is making the difference to the information consumer which will still exist but did not have much relevance in professional analytic tools.
One important thing: all of the book is written in German only … sorry!
UPDATE in 2021:
My article is part of this excellent book „Qalität und Data Science in der Marktforschung“ along with other very informative articles. You will get table of content and previews in the Springer Shop and this is also where you can order online, both as e-book and as printed book.

Title: Qualität und Data Science in der Marktforschung
Subtitle: Prozesse, Daten und Modelle der Zukunft
Editors: Bernhard Keller, Hans-Werner Klein, Thomas Wirth
Springer Gabler

Abstract
Datenvisualisierung, Visual Storytelling und Data Exploration sind wichtige Methoden, um gutes interaktives und erlebbares Informationsdesign zu entwickeln. Anhand der Applikation „Wohnungseinbrüche in Deutschland“ wird dargelegt, wie aus statischen Daten erlebbare Informationen mit hoher Interaktivität werden und damit Wissen und Verständnis effizient vermittelt werden kann. Zusätzlich wird erläutert, mit welchen Layoutmaßnahmen sich mehrere Informationsabschnitte zu einer kohärenten Webpage zusammenbinden lassen.
Kontext
Dies ist der zweite Artikel in meiner Folge, in der ich Webapplikationen analysiere, die im Rahmen meiner LV Multimediales Informationsdesign 2014/15 von Studenten am FB Online Medien erarbeitet wurden und die sich durch gutes, interaktives und zeitgemäßes Informationsdesign auszeichnen.
Innerhalb der studentischen Projekte sollten Inhalte aus Printberichten nicht nur in das Medium Web überführt und eine medienadäquate Benutzerführung entwickelt werden. Darüber hinaus sollten die Studenten die Inhalte mittels aktueller Webtechnologien visualisieren und interaktiv erlebbar machen. In der hier präsentierten Arbeit mussten dazu die im Printbericht vorhandenen Daten ausgewählt und eine neue Informationsarchitektur erarbeitet werden musste.
Innerhalb eines gegebenen Zeitraumes von 10 Wochen wurden die interaktive Webapplikation sowohl konzipiert als auch in einem funktionierenden Prototypen umgesetzt. Dieser Prototyp wird in diesem Artikel betrachtet.
Eckdaten zur prototypischen Applikation „Wohnungseinbrüche in Deutschland“
- Die prototypische Applikation ist hier aufrufbar. [Quelle 1]
- Sie ist für die aktuellen (2014/15) Versionen der Browser FF, Chrome, IE, Safari optimiert
- Ihr liegt das Kapitel „Thema aktuell: Wohnungseinbruchdiebstahl“ der als Printbericht publizierten „Polizeiliche Kriminalstatistik 2013“ [Quelle 2] zugrunde.
Adaptives One-Page Design als Layoutgrundlage
Die studentische Gruppe wählte aus der Datenmenge fünf Themen, deren Datenumfang entsprechend auf fünf Abschnitten darzustellen sind. Hinzu kommen die das Thema einleitende Startseite, eine Abspann-Seite und ein Impressum. Die gesamte Website, also die Summe aller einzelnen Abschnitte, ist als One-Pager mit einer konstant vorhandenen Navigationsleiste geschickt gestaltet, so dass der User sie sowohl linear durchscrollen kann als auch mittels der Navigation einzelne Themen direkt ansteuern kann. Nebenbei wird mittels kontrollierter Scroll-Transition erlebbar gemacht, dass der einzelne Abschnitt Teil einer einzigen Seite ist.

Abb. 1: Alle Abschnitte des One-Pagers „Wohnungseinbrüche in Deutschland“
Ein Vorteile des entwickelten Screendesigns ist, dass immer nur die Informationen des jeweiligen Themas betrachtet werden. Aus UX-Sicht wird dabei zum einen die kognitive Last für den Nutzer durch das Ausblenden nicht-relevanter Information begrenzt. Zum anderen wird die Website als eine Zusammensetzung verschiedener Seiten wahrgenommen, obwohl sie technisch und interaktionsdesignerisch eine einzige Seite ist. Dazu trägt wesentlich das adaptive Design bei, das den Hintergrund des jeweiligen Abschnitts formatfüllend an die jeweilige Monitorgröße anpasst und den Inhalt vertikal und horizontal zentriert. All diese designerischen Maßnahmen wurden mittels jQuery und fullpage.js umgesetzt.
Von statischer Datendarstellung zum interaktiven Informationsdesign
Führen wir uns vor Augen, was das Ausgangsmaterial der studentischen Gruppe war: ein PDF mit umfangreichen Tabellenwerken, durchsetzt mit einigen Charts und interpretierenden Texten, die Schwerpunkte in den umfangreichen Daten setzen und zusammenfassend interpretieren. Der vorwiegende Charakter aus Sicht des Kommunikationsdesigns ist der einer strukturierten Datensammlung. Alles durchaus lesbar für das Printmedium gesetzt; aber nicht geeignet, um den Leser zu motivieren, sich mit dem Kommuniziertem intensiver zu befassen. Der Bericht wirkt eher wie: „Wir haben eine Pflicht, die Öffentlichkeit über die Häufigkeit von Verbrechen zu informieren – hier sind unsere Ergebnisse.“ Und vermutlich – und völlig berechtigt – ist genau dies die Motivation des Printberichts gewesen.
Ganz anders war die Motivation der Studenten angesichts der Aufgabenstellung im Rahmen der Lehrveranstaltung. Es ging ihnen um die Visualisierung von kriminalistischen Key Indicators des Wohnungseinbruchs wie Tatzeit, Tathäufigkeit, Wohnsitz in Relation zum Tatort und anderen vorhandenen Daten, die Muster aufweisen können und die Anlass zur Hypothesenbildung geben. Sie blieben dabei aber nicht stehen, sondern gingen darüber hinaus. Es ging ihnen auch darum, die Daten zum Erzählen zu bringen, sie erinnerbar zu machen, das Erschreckende an der Häufigkeit dieses Verbrechens und der geringen Aufklärungsquote erlebbar zu machen, das Thema in einen Bezug zum Nutzer zu stellen. Aus dieser Motivation heraus entstanden solche Ideen wie der Einbruchszähler, die Textboxen mit starker Betonung der numerischen Werte oder der hoch-interaktive Vergleich von Täterprofilen.
In der designerischen Bearbeitung der einfachen Datendarstellung hin zur informierenden Erzählung erkenne ich vier Methoden – man könnte sie auch Prinzipien nennen – der Transformation der Datenpräsentation: Visualierung von Daten, Visual Storytelling, Data Exploration und Translation into the world of the user. Im folgenden werde ich diese Methoden anhand konkrete Abschnitte und Aspekte der Applikation „Wohnungseinbrüche in Deutschland“ beispielhaft darlegen.
Visualisierung von Daten
In der ursprünglichen Printdarstellung werden – nicht nur, aber vorwiegend – die Daten in Tabellenform dargestellt. Das Beispiel der Gesamtzahl der Wohnungseinbrüche in Deutschland in den Jahren 1999 – 2013 in Abb. 2:
![Abbildung 2: Wohnungseinbrüche in Deutschland 1999 - 2013. Tabelle aus dem Printbericht [2, S.53]](https://designforschung.files.wordpress.com/2015/08/wohnungseinbrc3bcche-in-deutschland-1999-2013-tabelle.png)
Abb. 2: Wohnungseinbrüche in Deutschland 1999 – 2013. Tabelle aus dem Printbericht [2, S.53]
- Alle Kategorien und Daten sind in der Bedeutung gleich gewichtet
- Dadurch wird Wesentliches von Unwesentlichem nicht unterschieden
- Bezüge zwischen den Werten, Muster der Werte, Minima, Maxima muss der Nutzer durch dediziertes Lesen und Vergleichen sich erarbeiten und das Erarbeitete sich merken
- Abweichungen vom Durchschnittswerten, mögliche Korrelationen und Verteilungsmuster sind nur grob abschätzbar
Im Vergleich zur Tabelle das kombinierte Zeitreihendiagramm in Abb. 3, bestehend aus gestapelten Säulen mit einer Prozentlinie, dazu eine Textbox. Hier der Link zum entsprechenden Abschnitt der Applikation.
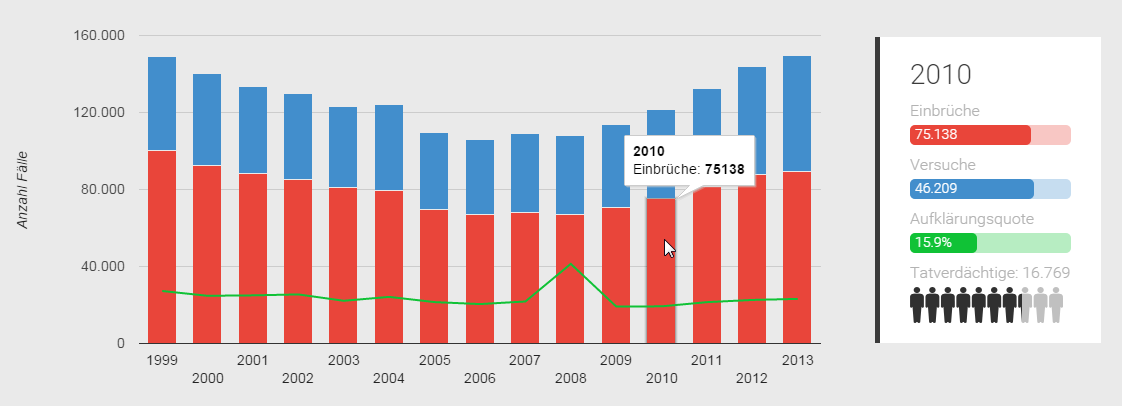
Abb. 3: Wohnungseinbrüche in Deutschland 1999 – 2013. Chart mit dynamischer Legende, Screenshot aus der Webapplikation
Ziele und Maßnahmen der Umgestaltung der Datenpräsentation waren:
- Nicht nur Daten darstellen, sondern aus den vorhandenen Daten Informationen schaffen
- Informationen so hierarchisieren und verknüpfen, dass Wissen daraus werden kann.
- Für den Erkenntnisvorgang Wesentliches herausstellen und leicht erfassbar zu präsentieren durch graphische Umsetzung numerischer Werte, d.h. durch Präsentation von Graphen, im englischen Sprachgebrauch üblicherweise „Charts“, im deutschen „Diagramme“ genannt.
- Wesentlich ist in diesem Abschnitt das Erkennen von Mustern in der Zeitreihe, also die Relationen der drei Variablen Einbrüche, versuchte Einbrüche, Aufklärungsquote zueinander innerhalb eines Jahres und ihre Entwicklung über mehrere Jahre.
- Die numerische Werte werden beim Hovern eines Datenpunktes in der rechten Textbox in einer hierarchisierten Textform dargestellt.
Die Datenvisualisierung ist ebenfalls Schwerpunkt meines zweiten Beispiels, dem Abschnitt, der die statistische Beziehung zwischen geographischer Lage der betroffenen Wohnung und dem Wohnsitz des Täters darlegt. Im Printbericht wirkt diese Information überschaubar:

Abb. 4: Wohnsitze der Einbrecher in Beziehung zum Tatort (2013) – Tabelle. Screenshot aus dem Printbericht. Quelle [2]
Der entsprechende Abschnitt in der Applikation besteht aus einer Kombination von Diagramm mit einer dynamischen Textbox.

Abb. 5: Wohnsitze der Einbrecher in Beziehung zum Tatort (2013). Screenshot des interaktiven Diagramms.
Die graphische Visualisierung mittels konzentrischer Kreise ist in der Kernidee klar und intuitiv erfassbar; ihr mangelt es jedoch an letzter Konsequenz, da weder Radien noch Flächen der verschiedenen Merkmalskreise die gegebenen Daten widerspiegeln. Eine gute Idee, die ausbaufähig ist.
Visual Storytelling
Ich habe einige Male erlebt, dass Visual Storytelling anfänglich so verstanden wird, als ob es darum ginge, passend zu den sachlichen Informationen eine Geschichte mit Akteuren, Orten und Handlungen sich auszudenken, in die dann die sachlichen Informationen eingebettet werden. Das ist nicht damit gemeint. Wenn ich dieses Verständnis anhand erster Ideenskizzen der Studenten erkenne, weise ich darauf hin, dass es nicht um eine Anreicherung mit weiteren Elementen geht, sondern um eine Reduzierung im Sinne einer Verdeutlichung. Visual Storytelling meint die graphische Inszenierung der Bedeutung von Informationen. Damit ist sie immer eine Interpretation und deshalb braucht es einen vorsichten und bewussten Einsatz dieses Prinzips.
Die Akteure des Visual Storytellings sind nicht erfundene Akteure, sondern die Daten. Um die Metapher der Inszenierung weiter zu führen: als Designer muss ich die Daten sprechen und agieren lassen. Das Layout ist ihr Bühnenbild, die Bühnenszenen sind die räumliche, interaktive oder/oder zeitliche Gliederung der Geschichte. Ihre Kostüme sind die graphische Ausprägungen, in dem die Daten auftreten: als beschriftete Zahlen, als Illustrationen der numerisch erfassten Kategorien, als Balkendiagramm oder auch als Tabelle …. Viele Kostüme sind möglich, aber es sind diejenigen zu wählen, die das Verständnis für den dargestellten Sachverhalt, für die Story, beim User am ehesten bewirken.
Die vorliegende Webapplikation weist keine breite Anwendung des Visual Storytelling auf. Lediglich im Abschnitt „Fakten“ werden stichwortartig Informationen mit Visuals verknüpft um schnell und pointiert zu kommunizieren: beispielsweise die überwiegende Anzahl an Einmaltätern oder den durch Einbrüche verursachten Schaden in Höhe von 427 Mrd. EUR allein im Jahr 2013.

Abb. 6: Fakten zu Wohnungseinbrüchen. Quantitative Informationen kombiniert mit Visuals.
Data Exploration
In der Applikation bündelten die Studenten mehrere umfangreiche Tabellen des Printberichts in einem Tool, das dem Nutzer die Möglichkeit gibt, innerhalb der Datenmenge selber zu explorieren: nach bestimmten Kategorien zu sortieren, Teilmengen der Daten nach bestimmten Filterkriterien zu sichten usw. Im Abschnitt „Die Täter“ kann der Nutzer zwei unterschiedliche Tatprofile konfigurieren und miteinander vergleichen, indem er nach verschiedenen Attributen (männlich oder weiblich, verschiedene Altersklassen, Einbruchszeit Tag oder Nacht, Deutscher oder Nicht-Deutscher) filtert.

Abb. 7: Konfiguration von zwei Tatprofilen und deren Häufigkeit 2013.
Die im Screenshot gewählte Konfiguration vergleicht die Anzahl von Einbrüchen tags mit nachts, begangen von Einbrechern beiderlei Geschlechts in der Altersgruppe zwischen 18 – 50 Jahre.
<Hinweis> Der Unterschied zwischen Tag und Nacht scheint nicht sehr groß zu sein. Der Blick in die 2015 publizierte Studie des GKV [Quelle 3] deutet aber darauf hin, dass eine präzisiere Datenerhebung sehr wohl präferierte Einbruchszeiten gibt – und zwar sowohl was die Monate betrifft wie auch die Uhrzeiten. Dies zeigt zum einen, dass zum Zwecke des Erkenntnisgewinns und für Schlußfolgerungen die Nutzung mehrere Datenquellen erforderlich ist und dass die Granularität der Daten maßgeblich auch die Möglichkeit seriöser Hypothesenbildung beeinflusst. </Hinweis>
Übersetzung in die Alltagswelt des Nutzers
Diese Methode zielt darauf ab, einen Bezug zur Welt und Umgebung des Nutzers schaffen. Ein überaus gelungenes Beispiel stellt die Webseite US Federal Budget Visualized dar, die das Billionen Dollar umfassende Budget der USA als Stapel von Geldmengen bildhaft darstellt und sie in Relation zu bekannten Dingen wie Sofas, Autos, Häusern und Wolkenkratzern setzt. Beeindruckend!
Im vorliegenden Fall blieben die Studenten näher am Boden: Es ging Ihnen darum, dass der Printbericht die Gesamtzahl von 149.500 Einbrüchen in Deutschland schlicht konstatiert. Wie lässt sich diese große Zahl dem einzelnen Nutzer nahebringen, fragten sich die Studenten. Die Antwort kam mittels einer kurzen Rechnung, nach der durchschnittlich jede dreieinhalb Minuten ein Einbruch begangen wurde. Von dort aus war es nicht weit zur Idee des „Einbruchs-Counters“, der die durchschnittliche Zahl der Einbrüche in der Zeit zählt, während sich der User mit der Applikation beschäftigt. Aus abstrakten großen Zahlen werden konkrete Bezüge in die Alltagswelt des Nutzers nicht nur benannt, sondern erlebbar gemacht.
Die textuelle Informationsform im Printbericht:

Abb. 8: Zentraler KPI-Wert „Gesamtzahl der Wohnungseinbrüche“ in der nüchternen Textform des Printberichtes.
Im interaktiven Informationsdesign wurde daraus folgende Form:

Abb. 9: Zentraler KPI-Wert, im Informationsdesign übersetzt in die Erlebniswelt des Nutzers.
Insgesamt nutzt die Webapplikation „Wohnungseinbrüche in Deutschland“ alle der vier o.g. Methoden, um interaktives und den User involvierendes Informationsdesign zu erzielen. Diese Methoden wurden in unterschiedlicher Qualität und Intensität verwendet: Visualisierung der Daten häufig und deutlich, Visual Storytelling in geringem Maße.
Wohnungseinbrüche in Deutschland: Zahlen und ihre Hintergründe
Die Beschäftigung mit den Zahlen hat über die designerischer Aufgabenstellung hinaus auch tiefere Neugier, Fragestellungen und durchaus auch Betroffenheit zum Thema ausgelöst – sowohl beim Dozenten wie auch bei der studentischen Arbeitsgruppe. So stellte sich beispielsweise für die Beteiligten die Frage, wie es denn zu erklären sei, dass NRW dasjenige Bundesland ist, das 2013 mit 313 Einbrüchen pro 100.00 Einwohnern nach Bremen, Hamburg und Berlin die höchste Einbruchsquote aufweist. Wir hatten dabei Medienberichte im Hinterkopf, in denen über ausländische Einbrechergruppen vorwiegend aus dem osteuropäischen Raum berichtet wurde. Nach unserer Vorstellung wäre die logische Konsequenz, dass Bundesländer wie Bayern, Thüringen oder Sachsen als östlich gelegene Bundesländer die höchsten Einbruchsraten aufweisen. Und nach der Datenlage waren sie es nun mal nicht. Wie geht das zusammen?
Nun, zuerst einmal können wir unsere empirische Basis verbreitern, da seit der Lehrveranstaltung die entsprechenden Zahlen aus dem Jahre 2014 veröffentlich wurden. Daraus hat die GKV eine Graphik erstellt, die zwar illustrativ etwas überzogen, aber dennoch sachlich richtig die geographische Verteilung der Quoten für Wohnungseinbrüche darstellt:
![Abb. 10: Wohnungseinbrüche 2014 - Verteilung nach Bundesländern [Quelle 3]](https://designforschung.files.wordpress.com/2015/08/wohnungseinbrc3bcche-2014-geographische-verteilung-nach-bundeslc3a4ndern.png)
Abb. 10: Wohnungseinbrüche 2014 – Verteilung nach Bundesländern [Quelle 3]
Wir ersehen daraus, dass auch 2014 NRW nach den beiden Stadtstaaten und Berlin immer noch die mit Abstand höchsten Einbruchsquoten aufweist. Insbesondere das Ruhrgebiet mit seiner dichten städtischen Bebauung bildet geradezu einen Hotspot der Einbrüche.
Ich habe in einer umfangreichen Reportage über Opfer und Täter in Krefeld Zusammenhänge gefunden, die erklären, weshalb gerade Städte im Ruhrgebiet diesen Hotspot bilden:
„So wie Victor H. in vielem typisch für die Diebe aus Osteuropa ist, so sind die W.s typisch für deren Opfer. Von Krefeld aus kann das strebsame Kleinbürgertum zügig die Betriebe des Ballungsraums an Rhein und Ruhr ansteuern, mit der Bahn oder mit dem Auto über die B 57 und die A 44. Doch während das Kleinbürgertum in Büros, Geschäften und Fabriken am Erhalt seines Besitzes und an seinem Aufstieg arbeitet und die Kinder in der Schule sind, pendeln die Diebe über dieselben Verkehrsadern in die tags verwaisten Wohnquartiere ein. Das dichte Netz aus Autobahnen und Schnellstraßen an Rhein und Ruhr ist perfekt für die Flucht. Darum kommen die Einbrecher nach Marl und Gelsenkirchen, nach Monheim und Bad Godesberg, nach Leverkusen, Recklinghausen, Mülheim an der Ruhr. Eine Klauhochburg liegt hier neben der anderen.
54.000 der knapp 150.000 Einbrüche des Jahres 2013 in Deutschland geschahen allein in Nordrhein-Westfalen. Insgesamt gab es in ganz Deutschland fast 50.000 mehr solcher Delikte als noch 2006 – ein Anstieg um ein Drittel. Statistisch gesehen erwischt es nun alle dreieinhalb Minuten jemanden. Nur wen, ist unberechenbar. Die Diebe aus Osteuropa, sagt der Polizist Uwe Laußmann, spähten ihre Opfer nicht groß aus. „Die fahren von der Autobahn runter, biegen zwei-, dreimal ab und legen los.“ [Quelle 4]
Noch einige Literaturhinweise zum fachlichen Thema Wohnungseinbrüche:
Ich empfehle die Reportage „Auf Raubzug in Krefeld“ allen Interessierten. Hier geht nur nebenbei um quantitative Dimensionen dieses Delikts. Im Fokus dieser Reportage stehen vor allem Einsichten in Umstände, Motivationen und gesellschaftliche Randbedingungen am Beispiel konkreter Menschen.
Die neuen Zahlen zu den Wohnungseinbrüchen für 2014 gibt es in der Polizeilichen Kriminalstatistik 2014. Der Artikel „Gelegenheit und Drogensucht machen Diebe“ in der FAZ vom April 2015 interpretiert die damals neu veröffentlichten Statistiken von 2014.
Eine kürzlich erschienene Studie GDV Einbruch-Report 2015 des Kriminologischen Instituts Niedersachsens [Quelle 3] beschäftigt sich ebenfalls mit Wohnungseinbrüchen; dabei aber schwerpunktmäßig aus der Perspektive der Opfer. Interessant finde ich vor allem der der Studie zugrunde liegende Perspektivwechsel, der nach den emotionalen Folgen für die Betroffenen und geändertem Verhalten und emotionalem Bezug zur Wohnung fragt.
Quellen
[1] Flaig, Henriks, Müller, Rascher: Wohnungseinbrüche in Deutschland. Arbeit im Rahmen der Lehrveranstaltung Multimediales Informationsdesign 2014/15, Fachbereich Online Medien an der DHBW Mosbach.
[2] Bundesministerium des Innern: Polizeiliche Kriminalstatistik 2013, Kap. 9 Thema aktuell: Wohnungseinbruchdiebstahl , S. 53 – 59.
[3] GKV: Mehr Schutz für den privaten Lebensraum. Einbruch-Report 2015 der Deutschen Versicherungswirtschaft, Berlin 2015
[4] Kowitz, Dorit: Auf Raubzug in Krefeld, in Die Zeit 9/2015

Abstract
Layouting GUIs for multi-lingual software requires often prediction of the screen space that is needed for terms in different languages and alphabets. In this article we examine a given set of 385 key terms used in balance sheet accounting multiplied by 11 languages with methods of descriptive statistics. We will find and discuss patterns and relations that allow to determine the required screen space if the length of the English term is given. Methods and rules of thumb are derived that can be applied by practitioners who are developing and designing user interfaces for multiple languages.
Why in English?
When some of my Czech colleagues recently were showing interest in reading some of my articles, I became aware that writing this blog in English rather than in German language would make the presented thoughts more accessible not only to my colleagues in Prague but also to other non-German speaking persons. That’s why I will try to write my articles in English language in general and see how this works out. However, articles which deal with websites and applications layouted, written and labelled in German language (like the ones my students are developing) will continue to be in German.
Screen space for translated terms
Some months ago I came across a database file which stores the terms used in balance sheet accounting translated into several languages. When working on screen design in multilingual software and content I had wondered if there is a way of estimating the space that is required by the different translations of a given word / term / sentences. Particularly if one is in the situation that the translations are not done yet which is quite common in the production process. The unwanted risk of reserving too little space for the translated terms is: cutting off the term or flowing over to other areas. On the other hand the risk of overestimating the space required by translated terms: wasting screen space and creating unwanted gaps in the layout. Both risks should be avoided. Sure, but how can we tell? Let me put the question in this way: Are there any rules or even algorithms that tell how long a foreign language term might become when it’s translated from English into another language?
When I looked at the translation data I thought I might be playing with them and see what I can find out when I apply some statistical methods to these data. I might even be able to provide some rules of thumb. We should keep in our minds that these rules are restricted to the domain of balance sheet accounting across several languages and cannot be generalized to languages in general. However, we will gain insights from which we can derive rules and approaches for practitioners in screen design and texting. Let us have a look first at the key data of the relevant data base.
Key data of data base
Industry: Financial, Domain: balance sheet accounting
Number of terms (in each language, except Czech): 386
11 Languages:
- English (EN)
- German (DE)
- Spanish (SP)
- French (FR)
- Italian (IT)
- Japanese (JP)
- Dutch (NL)
- Portuguese (PT)
- Russian (RU)
- Chinese (ZH)
- Czech (CZ)
We can consider the typographic parameters being normalized as all terms are formatted in Arial font with text size of 9 pt (in Excel).
Two examples, first hypotheses
Let’s look at one single example, the translations of the long term „Acquisition cost plant and factory equipment“.

Table 1: translations of a long term, displayed in Excel with Arial 9pt
Looking at the space occupied by the strings in the different languages we immediately can make a few observations in this particular example:
- The financial term does not consist of a single word but of a combination of several words.
- This applies also for the non-Latin language of Russian with Cyrillic. For Chinese and Japanese I just couldn’t tell by looking at the data.
- The smallest length has about 1/3rd size of the longest one.
- Chinese and Japanese need relative little space.
- Russian needs the most space.
- Some translations seem to incorporate abbreviations (German: „AHK“), others information added in brackets, making terms consisting of different words even more complex
Now let’s examine another example picked out of the database, the short term „Inventories“:

Table 2: translations of a long term, displayed in Excel with Arial 9pt
Some of the previous observations are confirmed, others are contradicted or need to be differentiated:
- In the second dataset the Czech translation needs most of the space, not the Russian translation.
- Chinese has still got the shortest length with two characters, but Japanese is quite wide.
One main observation of the term „inventories“ is that every translated term (including the english term itself) is much shorter than in the previous example. So we might suppose that there is some correlation between the length of an English term and its counterpart in other languages. The underlying reason for this one can call evident or even trivial: Simple things need only a short description in any language. To put it the other way round: if we have to describe something complex, we will need several words than describing something simple, in English language as well as in any other. And this relation of shared growth of term lengths might be stronger than the differences between our eleven languages – not necessarily in any case but as a general tendency. This is something to be examined later on as correlation between termlenghts of different languages.
Skimming through all the translations of 386 terms seems to confirm most of the observations made above. In order to get a better overview over the data let us focus first on counting the number of characters (= letters and spaces a term consists of). But before doing this we should state that number of characters of a term does not necessarily equals required space. Languages with Latin alphabet may differ in length depending on the frequency of letters in that particular language: „m“s require more space than „i“s. More important, there seems to be a visually large difference between Latin alphabet and non-Latin ones: We just need to look at our two examples shown previously to notice that Russian, Japanese and Chinese characters seem to require more pixel-width than the average Latin character. However, we start with counting the number of characters of each translated term (see this spreadsheet file „Term Lengths and Means per Language“ in googledocs) keeping in mind that this is not yet the metric we want to have in the very end.
Central Tendency of Term Lengths in different Languages
Let’s start having a look at the arithmetic mean of all the lengths across one particular language and compare those means in absolute numbers.

Graph 1: Means of Terms Lengths by Language
What we can read about the means from Graph 1:
- European languages range from 24.8 (English) to 32.4 (German) characters for the average term in this dataset of balance accounting terms.
- German language has the highest mean of all 11 languages which seems to confirm the general opinion that German texts „run“ rather long.
- Asian languages have dramatically low numbers: The average term counts 7.1 (Chinese) and 8.0 (Japanese). This is in line with our observations of the examples above as documented in Screenshots 1 + 2.
- Russian language is running with Cyrillic alphabet with 31.9 characters for the average term quite long as well, almost as long as German.
We can look at the same values from the English language point of view and compute ratios. To do so the average number of characters being 24.8 in absolute numbers is set to factor 1.0; the other values tell us which ratio the average term length has in the related languages. For instance, we compute that the average term length in German has a ratio value of 1.31 which says it does exceed the average English term length by nearly 1/3. On the other hand, the average Japanese term length is 0.32 and that tells us that in Japanese terms require only 1/3rd of the number of characters than in English. After all, this is giving us already quantitative information.

Graph 2: Ratio of Mean Term Lengths – Language Y vs. English
Taking a look at German
Let us take a closer look at the relation between English and German. From the above figures we derived already that we will need 1/3 more characters for a German term when we translate it from an English term of average length. Some examples from the primary data set are confirming this rough guess:
- EN: „Other short-term payables“ (25 char’s) > DE: „‚Sonstige Zahlungsverpflichtungen“ (32 char’s)
- EN: „‚Bank loans and overdrafts“ (25) > DE: „‚Bankdarlehen und Überziehungskredite“ (36 char’s)
If we filter all English terms with 25 characters (which is the mean for English) we notice that a few of the German translations are having less than 25, but the majority has clearly more than 30 or even 40 characters as Table 3 is showing.

Table 3: All English Terms with 25 characters and their German translations
This example let a derive a very rough rule of thumb:
Terms dealing with balance sheet accounting translated from English to German require often 1/3rd or more of term length.
Of course, this is not a scientific deduction; for instance we did not yet look at all the other English terms with more or less than 25 characters. Nonetheless, in some daily layout task applying such a rule of thumb might be better than just knowing nothing about the screen space that needs to be reserved. Before we move on to a broader view looking at the data, let’s switch the perspective to German language for the sake of German designers. We already found out that in our dataset the German terms have the highest number of characters in average. If we normalize Graph 1 to the mean of German terms we get a clear picture of the relations in Graph 3 and this differs a lot from the English perspective we saw before.

Graph 3: Ratio of Mean Term Lengths – Language Y vs. German
Compared with German, the average term of no other language is longer. The closest is Russian with a character length being 98% of German terms, which could exceed required space as the Cyrillic alphabet seems to have more character width – we will examine this aspect later on.
The conclusion comes to our mind that we do not need to care much about reserving additional space for other languages once we do the layout with German terms. Any of the other languages needs fewer characters. So this might be another insight from our data analysis. The Asian languages are placed at such low ratios against German, that it seems to be very unlikely that Japanese and Chinese terms exceed their German counterparts. And in fact: filtering the German terms with extreme few characters in the data set shows that the Chinese terms do not undercut their length, so it looks reasonable to assume that in almost every case the Asian term runs shorter than the corresponding German term.
From a designers perspective, there might a design danger be lurking from an unexpected side that we would need to keep an eye during layouting: such low ratios might result in a layout that could look unbalanced in Asian version because only a few letters occupy a space which had been designed for something four times larger.
Distribution of term lengths in different languages
Until now, we have been looking at the term lengths by the their central tendency in the different languages. We compared some of the means but became aware we need to look at all of the term lengths and their frequency within a particular language. Let’s now examine the distribution of all term lengths within one language and let us then compare the results across languages.
We are graphing histograms [Harris 1] along each language. In each graph we are transforming the discrete variable of term length (values can only be integers) into an interval variable that aggregates term lengths into bins starting from 1 up to 64 characters by steps of 4. This is what the frequency distributions look like for English and German if visualized as histograms:

Graph 4: Histograms of Term Length EN vs. DE.
The comparison of histogram of German with English terms shows:
- Both distributions have a positive skew: the maxima are more to the lower end of the x-axis and we have a tail to the right.
- English terms have no more than 52 characters
- English terms have a clear frequency maximum around x(EN) = 20
- Germany has no clear maximum but rather a plateau ranging from x(DE) = 20 to x(DE) = 32
- German seem to decrease in frequency f(G) after passing its high plateau but increase again towards the end of x(DE) = 64. Among all 11 histograms, German is the only language showing this characteristics and this needs a closer look at the primary data.
What we can see immediately from looking at the primary table being filtered with x(DE)=62,63,64 that some of the longest German terms are already abbreviated. Due to technical reasons the regular translation was already shortened by the translators to avoid exceeding 64 characters. Without this technical constraint the abbreviated terms would have had even more letters. In the histogram this would result in an even longer right tail and each bin showing fewer counts. So we can explain the unusual pattern in the DE histogram with two combined factors: First, German language is consuming per se a lot of letters for the given terms. Second, with a jam because of the technical limit not allowing more than 64 characters.

Table 4: Extreme long German Terms and their english counterparts
Taking a look at the primary data with filtering only the German terms with 63 to 64 characters (Table 4) tells us that in this results truncations are quite heavily applied; like in the example „Kum. Abschr. auf and., sachgerecht bez. Gruppen von Anl.-Gegenst“. In addition, we can observe that other translations followed the German abbreviations (e.g. English abbreviation „acc“ („accumulated“) for German „kum“ („kumuliert“) or left away certain parts of the German term (e.g. English „Materials“ for German „Materialaufwand (Roh-, Hilfs-, und Bestriebsst., Waren/Leistungen)“.
Let’s now extend the scope of our examination towards the frequency distribution of term lengths across all 11 languages. I have grouped the languages in the resulting multiple histogram by their well-known relation to the language families Germanic, Romanic, Slavic and Asian.

Graph 5: Multiple Histogram of Term Length – by Language
Looking at the histograms we get some insights into the characteristics:
- Strong confirmation that Chinese and Japanese terms are way shorter than their counterparts in the Germanic, Slavic or Romanic family.
- The Romanic languages SP, FR, IT, PT are similar to each other which was expectable from the well-known similarity of Romanic languages in words and grammers.
- But they don’t look that much different to the Germanic Dutch or Slavic Czech, which was a bit surprising me.
- Just Slavic Russian seems a have a different pattern as very long terms seem to happen quite often. This fits to our previous calculation that Russian is having the second highest mean. But then again: the visual pattern of the Russian histogram does not completely different to, let’s say, Spanish.
- And the pattern of Slavic Czech looks more similar to any of the Romanic languages than to Russian.
After all, the comparison of histograms does not give us very much precise rules when we think about the original aim of reserving space for translated terms. They give us rather a general impression about term lengths. But it is not yet clear if short English terms result in short German / Russian / French / … terms as well and what range of term length we can expect. If we want to examine this question we need to change our approach from analysing one variable to looking at the relation between two variables.
Contingency Tables and Scatterplots
In the next step we will look at the English terms as being one variable and any other language being a second variable. On the basis of our term length data we identify which English term lengths (x) result in which length (y) of another language and aggregate the frequencies in a contingency table. A contingency table gives the frequency f(x,y) of different combinations of values of two (or more) variables.
Scatter graphs (also „scatter plots“) are visualisations of two variables [Harris, 2]. They are useful to convey information about association between the two variables. In order to transfer the contingency table into a scatterplot, we transfer the table into cartesian coordinates. The x-axis represents the length of English terms, the Y-Axis that of the translated language which we want to call Y-Language. Each occurence of a English term with the length x(EN) being translated into the language Y with the length y(Y) results in a point in the cartesian plane. (x,y)-tupels which have no occurrence, i.e. f(x,y) = 0, are left empty. Tupels which occur more than once would be overplotted using this method. In statistics for this case the method of jittering is applied which adds some noise to the values resulting in placing the points near to each other instead of on top. I personally don’t like this visualisation workaround for its unprecision.
From the perspective of data analysis, the question is how we can graph a third dimension. For this case Exel is offering a 3D-Scatterplot-Chart. However, in our case with a range of 64 x-values and 64 y-values the result became quite unreadable. As our 3rd dimension frequency ranges only from 0 ≤ f(x,y) ≤ 14 and only very few are beyond the values of 4, an alternative solution could be to encode the frequency by different shades of the same color via conditional formatting of the cell. The resulting scatterplot is depicted in this tabular scatterplot realized in this google spreadsheet „Scattergraphs of Term Lengths across two languages“
Another approach is to apply transparency to the dots which also results in having a darker color where dots are plotted on top of each other. This is the method I have used to produce the scattergraphs depicted in this article.
Term Lengths English – German
Let us first analyse the relation between English and German term lengths in Graph 6. Every dot in the graph is showing one or more occurences with an English term of a length x and its German counterpart term with the length y. The darker the dot-color, the more frequent this tupel (EN,DE) occured. The resulting scatterplot is enhanced by a light grey diagonal which is showing where an English term and its German translation have exactly the same amount of characters. Not unexpectedly this does not happen very often. Nonetheless, this diagonal seems to be some kind of attractor as the dots are scattered along this diagonal. This pattern is showing us the force of positive correlation between these two languages, expressing the tendency of German translations to get longer in the same degree as the English do.

Graph 6: Scatterplot Term Lengths EN – DE
However, from being more dots being above the diagonal than being below we can read that it is more likely that the German term is longer than the corresponding English. And we can notice at the upper end of the GE axis that a lot of terms have the maximum length of 64 characters and this happens even more frequent when the English terms are between 40 and 50 characters. The blue line is the regression line based on a linear model; within this context we should regard it as summarizing the correlation between our two variables.
This same scatterplot supplies a complete second point of view, which is that we can also look from German perspective. We must only follow the values on the y-axis to the right to find out what is happening to German term lengths when they are translated to English. By this we can see that no dot is placed beyond x=51, meaning that no English term is longer than that – whatever the length of the German one. Of course, we could have concluded that from the histograms, but now we see it! And we see by looking at how many dots are placed left or right to the diagonal, that in general the English translations are shorter than the German terms. If they are longer, they are not exceedingly longer as those dots being right to the diagonal are close to it.
I consider this to be quite informative when being faced with the problem of reserving space for translations that we started off with. And I wonder if the conclusions could be applicable to language characteristics in general beyond the small and domain-specific set we use here. Anyway, let us continue looking closer at the relationships between the English and some other languages.
Term Lengths English – French
Right from the very first glance this Plot looks very different to the EN – DE graph. We see that all dots are quite close to the diagonal. This tells us that French terms do not differ much from their English counterparts.

Graph 7: Scatterplot Term Lengths EN – FR
A few exceptions can be observed near x = 48. However, the correlation appears visually to be very strong, which is confirmed by an calculated correlation coefficient r = 0.89. Also the vertical and horizontal distance of the tupels look quite symmetrical which can be interpreted that in general the term length does not change dramatically when terms are translated.
Term lengths English – Japanese
The scatterplot of English and Japanese terms shows a different pattern with some similarities to the previous one. As in the French graph, the dots are scattered around the regression line. The regression line is in this case not running parallel to the diagonal.

Graph 8: Scatterplot Term Lengths EN – JP
Except one occurrence all Japanese terms have less than 20 characters. The bulk of terms is concentrated with 8 or fewer characters as we can derive from the darker dots being placed at 4 < x < 24. No dot is above the diagonal, so that we can conclude: whatever the English term, no Japanese translation will have more characters. However we need to remind ourselves that the required space might be more as Asian characters appear to be wider than the average Latin character.
As the bulk of the data points are scattered along a line we can assume a positive correlation: the longer the English term the longer the Japanese term. This is confirmed by r = 0.73. However, from the plot we get the impression that this progresses in a much slower rate than in the non-Asian languages. This can be stated more precisely by the gradient b of the regression line being computed as b = 0.27.
From Characters to Pixels
Until now, we have been comparing the number of characters in our 11 languages and found some typical and atypical characteristics by applying methods of visual analytics. In order to move on to the initial aim of estimating necessary screen space, we still have to convert the term-length into pixel width used by the characters of the different languages.
For simplicities sake, we assume that all languages based on Latin alphabet (Germanic, Romanic plus Czech) use short letters like „i“ or „t“ and wide letters like „m“ in a similar proportion – as a look on the primary data might be enough right now to justify this assumption. Cyrillic and both Japanese and Chinese seem to have letters that on average need more space. We want to quantify this by measuring the pixel width of the average character ( i.e. letter and space) in each of the alphabets.
We are using a half-manually method: Google Spreadsheet is measuring the pixel-width of a column in pixel (contrary to Excel which is using a different unit, see article Pixel, Point und Zentimeter in Excel), so that we can read the pixel-width from the software instead of measuring this via a pixel based tool like Photoshop. We are picking a few terms from the different languages, based on using Arial with size of 11 which comes visually next in text size to Arial 9pt in Excel. (No idea, why the textsize definitions differ in these two softwares, but the important thing – the ratio between the average character width – remains the same as everything is scaled up or down). After calculating the pixel width of the average characters we get the following values:
Table 5: Pixel Widths of average Characters
We can roughly conclude that the average Cyrillic letter needs 10% more width than the average of the Latin alphabet and that both Asian languages require 110% more width than Latin for their average character. This is quite a change in the game and requires that we move on to adjusted scatterplots with units being converted to pixels.
It will result in Russian term lengths being longer than we have been seen in number of characters. As for Japanese and Chinese, we now can estimate that some of Asian terms are even longer in pixel width than their English counterparts, particularly in the short English terms, and we will see proved in the scatterplots for Japanese and Chinese.
I have converted the scatterplots English – Language Y, which were based on the unit [number of characters] to the unit [pixel size], with their textsize being Arial 11 in Google spreadsheets. From comparing the different scatterplots we can conclude for needed screenspace for balance sheet accounting terms:
- The dominant factor is in general the length of the English term. The term length in any language correlates in a positive linear way with the English term length more or less. The correlation is smallest with German (r = 0.695) and the highest with Romanic languages (for example Spanish with r = 0.906).
- Thus, if you have the choice: start your screendesign with English terms.

Graph 8: Terms Lengths English and Language Y. Units in px based on Arial 9pt. Green Line = Added Pixel Constant to English Term Length.
Visual estimation of required additional pixel width
My idea is now to add on top of the English term length a particular pixel amount that will cover additional length when the English term is substituted by the translated term. The precise number of this constant varies according to the different languages and the absolute number dependent on the text size. However, the ratio of the constants remain basically the same as long as all the terms in the different languages share the same text size. Recommendations I have been heard like „add 30% of length“ do not reflect the full range of values and don’t accomplish the task particularly in the lower percentile of the values.
The summand is rendered as a green line running parallel to the diagonal. All data points underneath this line will fit into the reserved screen space when the summand is added to the length of the relating English term. In the underlying computation of the scatterplot we can easily apply different values for this constant. Just by looking at the amount of dots above the green constant line we know exactly how many terms would be truncated and we can decide if we accept that or want to apply an ever higher constant.
Let us have a look at the additional pixel widths required when our terms from the primary data set are substituting the English terms:
English > French / Italian / Spanish / Portuguiese / Dutch
For Romanic languages and Dutch, most of the translations will be wider than the English term, but in a proportional way. Using an additional 150 px on top of the pixel with of each English term will make sure that no term of these languages will be cut off.
English > German
If you need to be on the safe side and no truncation can be applied to German terms you should reserve space for all 64 characters respectively 406 px in Arial 9pt. Alternatively we could apply additional 150 px (which is a space of about 21 „n“s in Arial 9 pt) on the cost that a very small part of the terms (those above the green line) will be truncated.
English > Russian
Russian is correlating to English term lengths quite well, but not as good as Romanic languages. We need to add a larger screen space of 190 px to the English term and will have only very few translations been truncated.
English > Czech
To my surprise, the additional space of 150 px being added to the English term length covers almost all of the Czech terms. Merely 11 out of the 386 data points lay above the green line.
English > Japanese
Though Asian letters are much wider than Latin characters, the very large majority of japanese terms still require less space than their English counterparts. By adding 60 px (or 9 „n“s for fontsize independent) on top you make sure that nothing will be truncated. <Remark> The 5 Japanese terms above the green line contain Latin characters which make them less wider in width than calculated for the graph </Remark>
English > Chinese
Basically the same applies as in Japanese, but with fewer outliers.
Some concluding thoughts on the topic, which might include some take-aways
- If you have got all the translations at hand and use scatterplots, then you can precisely compute which space you need to avoid that terms are cut off.
- By applying the method shown above you can literally see how many (and even which!) terms will be truncated if you need to reserve less screen space.
- Correlation rules: The longer the English term, the longer will be the translated term – as a tendency but not in all cases.
- If you do the layout using English terms, your chances are high that the translated term will be longer but not exceedingly longer. At least translating into Romanic languages and Dutch, surely in Japanese and Chinese.
- Different Alphabets are an important factor for required screen space (based on using the same font and textsize).
- Term length can be measured in two different units: number of characters or pixels. Number of char’s keeps you independent from font and font size; using pixel units keeps you tightened to a particular font size. However, when calculating screen space for layouts you might need both units.
Of course, the findings of this article cannot be generalized beyond the domain of balance sheet accounting. However, it can create some indicators for the space required by different languages.
I have shown some methods to calculate very precisely spaces once most of the terms within the one domain are known. This knowledge should be preserved, analysed and documented so that we can it apply the next time a similar situation occurs. If we examine terms in different industries, maybe we can confirm some basic associations we have found above. Future work?
I wonder how companies which are localizing their software are dealing with this problem. Does anyone know more about this?
Literature
[ 1] Article „Histogram and Frequency Polygon“ in Harris, Robert L.: Information Graphics – A Comprehensive Illustrated Reference, New York 1999, p. 187ff.
[ 2 ] Article „Correlation Graph“ in Harris, 1999, p. 110 ff.
<Hint>This is THE REFERENCE for Charts and Diagrams. Needs to be on the shelf of every Information Designer.</Hint>
I want to recommend two other books on statistics:
Field, Andy et al.: Discovering Statistics using R, Los Angeles, 2nd edition 2013. A work of epic dimensions. <Warning> This book could be used to kill human beings in two ways: either by throwing the book with a weight of 2.340 kg at them. Or by letting them learn Statistics via R on 956 pages. I think the second death is worse. </Warning>
Hengst, Martin: Einführung in die mathematische Statistik und ihre Anwendung. Mannheim, 1967. <Personal remark> This is a book in the academic serie „BI Hochschultaschenbücher“. Very compact statistical knowledge on university level. I bought it back in 1971, but did not read it at that time. However, when I started discovering statistics four years ago, I was glad about its mathematical and roots-oriented approach. No Excel, no R, no computer, even no Desktop Publishing. At that time all diagrams had to be drawn by hand. It seems to be a bit out-fashioned by now but I like it just for this. There does not seem to be a updated edition. Rather 10 books from 1967 available at Amazon. </Personal Remark>
Abstract
NUIs als aktuelle Leitmedien verändern tradierte Designparadigmen. Als Folge ist in Arbeiten von jungen Webdesignern eine Abwendung vom starren funktionalistischen Design und eine Hinwendung zum Einsatz von Transitions und Animationen zu erkennen.
Aithalides analysiert die Highlights einer solchen Arbeit auf dem Hintergrund einer Printpublikation zu Nutzertypen in Deutschland. Die daraus in der interaktiven Applikation entstandene Dynamisierung von Information wird aus informationsdesignerischer Sicht untersucht und mit einem konventionellen, funktionalistisch geprägtem Designverständnis kontrastiert.
Kontext
Im Rahmen meiner LV Multimediales Informationsdesign 2014/15 erarbeiteten Studenten des Fachbereichs Online Medien zu verschiedenen Themen Webapplikationen, die sich durch gutes, interaktives und zeitgemäßes Informationsdesign auszeichnen: unter Anwendung reichhaltige Interaktion, schlüssige Narration und leicht verständliche Exploration. Was diese schlagwortartigen Begriffe bedeuten, wird in der Analyse der einzelnen Applikationen und der Diskussion der designerischen Hintergründe hoffentlich deutlich werden.
Den Applikationen lagen in Printform veröffentlichte Broschüren zugrunde; dabei sollten die Inhalte nicht nur in das Medium Web überführt werden und eine medienadäquate Benutzerführung geschaffen werden. Vielmehr galt es, die Inhalte mit den Möglichkeiten des neuen Mediums zu visualisieren und mittels Interaktionen erlebbar zu machen. Dies konnte auch dazu führen, dass die im Printbericht vorhandene Struktur verändert oder sogar komplett über Bord geworfen und eine neue Informationsarchitektur erarbeitet werden musste. Da die Arbeitsergebnisse nicht nur konzipiert, sondern in einem funktionierenden Prototypen umgesetzt werden sollten, mussten die Studenten innerhalb des gegebenen Zeitraums von 10 Wochen auch reichlich handwerkliches Knowhow zu CSS3 und verschiedenen JavaScript-Libraries erwerben, testen und anwenden.
Dieser erste Artikel in dieser Folge betrachtet die Applikation „Nutzertypen in Deutschland 2014“, der ein Kapitel der Studie „D21 Digital-Index 2014“ zum Inhalt hatte.
Eckdaten zur Applikation „Nutzertypen in Deutschland 2014“
- Die Applikation wurde für die folgenden Browser optimiert:
- Safari 8
- Chrome: leichte Darstellungsfehler
- Firefox und IE stellen die Applikation nicht korrekt dar.
- Die in diesem Artikel vorgestellte Applikation „Nutzertypen in Deutschland 2014“ kann jeder hier aufrufen.
- Zugrunde liegender Printbericht: D21 – Digital – Index 2014, Kapitel 2: Nutzertypen. Wer ist die digitale Gesellschaft?
Fachlicher Hintergrund der Applikation
Die Initiative D21 hatte 2014 eine empirische Studie veranlasst, die zum Ziel hat „… den Grad der Digitalisierung in der [deutschen] Bevölkerung in ihrer Vielschichtigkeit zwischen Leben und Arbeiten aus der Perspektive der Bürgerinnen und Bürger zu messen …..“ [2, S. 7]. Das finde ich an sich schon mal interessant, dass erkannt wurde, dass sich Digitalisierung nicht in der Auflistung von Hardware-KPIs wie Datendurchsatz, Breitband-Versorgung und Anzahl der verkauften Computer erschöpft, sondern dass es erforderlich ist, das Phänomen „Digitalisierung“ aus der Perspektive des Anwenders und seines Verhaltens und seiner Einstellungen zu denken und zu erfassen. Fragen zu stellen wie z.B.: Welche Geräte und Services werden in welchem Umfang genutzt? Zu welchem Zweck? Wenn sie nicht genutzt werden – weshalb werden sie nicht genutzt? Für mich ist das eine Untersuchung, die fundamentale Kennwerte (KPIs) zur User Experience mit den digitalen Medien identifiziert, systematisch erhebt und quantifiziert.
Für die Studie wurden über 200 Einzelinformationen identifiziert, die sich vier Themenbereichen (im Bericht „Dimensionen“ genannt) zuordnen lassen:
- Zugang – Nutzung der digitalen Infrastruktur
- Nutzungsvielfalt – Nutzungsintensität und Nutzungsvielfalt
- Kompetenz – Wissen über digitale Themen, technische und digitale Kompetenz
- Offenheit – Einstellung der Bevölkerung zu digitalen Themen und Neuerungen ( Ängste, Befürchtungen, Chancen, Vorteile)
Diese vier Themenbereiche stellen auch gleichzeitig die vier Komponenten des Digital-Index dar; jeder der vier Bereiche fließt als Sub-Index mit unterschiedlichem Anteil in die quantitative Gesamtgröße ein. Bestimmt wurde die Gewichtung des Anteils mittels Expertendiskurs [2, S. 8]. Die repräsentative Datenerhebung erfolgte mittels Befragung zur Ermittlung des aggregierten Gesamtgröße, des „D21 Digital-Index“ (n= 2995) [2, S.5]
Mittels statistischer Clusteranalysen wurde nach Gemeinsamkeiten und Unterschieden in der befragten Bevölkerung gesucht und als Ergebnis sechs verschiedene Nutzertypen identifiziert, die jeweils durch eine Adjektiv-Substantiv-Kombination benannt werden. Die errechneten Anteile der jeweiligen Typen an der deutschsprachigen Wohnbevölkerung ab 14 Jahren mit Festnetz-Telefonanschluss im Haushalt sind:
- Außenstehender Skeptiker: 26%
- Häuslicher Gelegenheitsnutzer: 30%
- Vorsichtiger Pragmatiker: 7%
- Reflektierter Profi: 18%
- Passionierte Onliner: 13%
- Smarter Mobilist: 6%
Soweit der zusammengefasste fachliche Hintergrund der erstellten Webapplikation, wie er im Printbericht dargelegt ist.
Informationsarchitektur, Benutzerführung und Navigation
Die Aufgabenstellung an die studentische Projektgruppe lautete, die Inhalte des Kapitels „Nutzertypen“ auf eine interaktive Applikation zu heben und erlebbar zu gestalten.
Ohne eine kurze Darstellung, was die Studie will, was der Digital-Index ist und wie er sich zusammen setzt, sind gewisse Detailinformationen im Kapitel nicht verständlich. Dies hat Konsequenzen für die Informationsarchitektur der Webapplikation: Die Projektgruppe setzte daher einen linearen Screenflow als Vorspann an den Anfang der Applikation, um mittels Text und Grafik diesen Kontext dem Nutzer vorab zu kommunizieren.

Abb. 1 — Informationsarchitektur der Applikation „Nutzertypen in Deutschland 2014“ nach dem D21-Digital-Index. Man beachte den Vorspann vor der eigentlichen Homepage.
„Vorab“ meint dabei: vor dem Übersichtsscreen über die sechs Nutzertypen. Dieser Übersichtsscreen wird als eigentliche Homepage verstanden und folgt darin auch dem Aufbau der gedruckten Broschüre, die auf einer Doppelseite einen Überblick über alle Nutzertypen gibt und deren wesentliche Eigenschaften qualitativ und quantitativ darlegt, bevor auf den folgenden Seiten der Steckbrief jedes einzelnen Typus auf einer Doppelseite erläutert wird.
In der interaktiven Webapplikation wird visuell jeder Nutzertyp durch eine Illustration der kennzeichnenden Eigenschaften sowie durch eine spezifische Farbe kodiert. Verglichen mit dem Printbericht wurde das Informationsdesign des Übersichtsscreens wesentlich verbessert: die Größe der farbigen Kreise korreliert mit dem Anteil des Typus an der Gesamtbevölkerung. Zusätzlich werden die Nutzungstypen entlang einer x-Achse entsprechend der Größe des Digi-Indexes angeordnet.

Abb. 2 — Die Homepage der Applikation: Übersicht der sechs Nutzertypen mit ihrem Digitalisierungsgrad und dem jeweiligen Anteil an der deutschen Bevölkerung.
Unterhalb – dieses örtliche Attribut ist im Sinne der IA als hierarchische Verortung gemeint – der zentralen Homepage kann der User frei navigieren. Durch Selektion eines Nutzertypen werden Seiten zugänglich, auf denen die Details zu den Subindikatoren dargelegt sind. Navigiert wird zwischen diesen Detailseiten durch Klick auf die horizontal angeordnete Subindikatoren-Leiste am unteren Screenrand. (siehe Abb. 3 Pageflow)
Zur Übersicht und zur Rücknavigation dient die hierarchische Navigation, die visuell als bogenförmige Gruppe von farbigen Kreisen am rechten Rand des Viewports dargestellt ist. Sehr gelungen ist bei dieser Navigation, dass alle Teile der Applikation (Vorspann, Übersicht Nutzertypen, Digi-Index jedes Nutzertypen) in jedem Screen sofort erreichbar sind.

Abb. 3 — Pageflow vom Übersichtsscreen zu den Detailinformationen der einzelnen Themengruppen innerhalb eines Nutzertyps. Hier Screenshots am Beispiel „Reflektierter Profi“.
Klassische Contentnavigation in neuem Look
Wegweisend für gutes interaktives Informationsdesign finde ich in der Applikation die doppelte Funktion vieler Informationselemente: zum einen sind sie Träger von Informationen, gleichzeitig sind sie aber auch Navigationselemente. Am Beispiel des Screens „Reflektierter Profi“: Das Feld Kompetenz in der unteren Dimensionsleiste zeigt die Punktzahl 68 dieses Subindexes für diesen Nutzertyp, gleichzeitig ist dies aber auch ein Sprungpunkt um zum Screen „Kompetenz“ mit den entsprechenden Details zu gelangen.
Die Absicht – oder in der UX-Sprache: die Teilaufgabe – des Nutzers ist hierbei ein Drilldown. Dieser Begriff kommt aus dem Online Analytic Processing (OLAP) und meint das Hineinzoomen in hierarchisch strukturierte Daten um eine Analyse zu verfeinern.
Die Methode, um den Nutzer dies durchzuführen zu lassen, ist die klassische Contentnavigation, so wie sie auf vielen Verzweigungsseiten im Web schon seit etlichen Jahre Anwendung findet. Insofern wurde in der vorliegenden Applikation die Methode der Teaser angewandt und ist nicht ungewöhnlich, sondern Best Practice. Was im vorliegenden Fall aber ungewöhnlich ist, ist die Formgebung dieser Teaser als Bubble. Das hat damit zu tun, dass die studentische Arbeitsgruppe die Kreisgestalt als visuelle Leitmotiv der Applikation wählten – wie sich unschwer anhand der Screenshots in Abb. 3 erkennen lässt. Darüber hinaus aber habe ich beim Navigieren gar nicht den Eindruck, unterschiedliche „Seiten aufzurufen“. Vielmehr fühlt sich so an, als ob die gewünschten Informationen auf meine Klicks auf ein und dieselbe Bühne gerufen werden und dabei einer Choreographie folgen. Das hat viel mit dem Konzept belebter Elemente zu tun. Doch dazu später mehr.
Momentan möchte ich darauf verweisen, dass hinter der Gestaltung dieser Contentnavigation die Absicht stand – und auch spürbar ist -, den User dazu zu bringen, den Informationsraum zu erforschen und sich dabei frei bewegen zu können. Der User soll explorativ den Informationsraum zu den verschiedenen Nutzertypen erkunden können: Drilldowns, Querbezüge, Rollups erforschen können und sich auf seine Weise die Informationen aneignen und verstehen können. Dies ist eine andere, ja geradezu gegensätzliche kommunikative Absicht als die des Vorspanns, bei dem es darauf ankam, in kurzer Zeit einige wenige, aber wichtige Informationen zu vermitteln.
Lässt man den User einen Informationsraum explorativ erkunden, so geht man als UX-Designer immer das Risiko ein, dass der Nutzer mit bestimmten Bereichen gar nicht in Berührung kommt; daher ist die Konzeption explorativen Vorgehens nicht in allen Nutzungssituationen oder Nutzungszielen sinnvoll. Auch die Verdichtung und Verlagerung von Informationen bedarf der Berücksichtigung von kognitiver Last des Nutzers und Steuerbarkeit der Applikation. Im der vorliegenden Applikation „Nutzertypen“ merkte ich an mir selber beim Durchklicken, wie sehr das Spielerische und die Freude am Entdecken in mir angesprochen wird. Der Reiz des Ausprobierens, ob und wie „es weiter geht“ führt zu einer Leichtigkeit im Umgang mit dieser Applikation, die den Nutzer in die Applikation und ihre Inhalte involviert und eine nachhaltige positive User Experience schafft.
Entzerrung von Information durch Verlagerung auf Interaktionsebenen
Damit Exploration als reizvolle Erkunden eines Themas und nicht nur als orientierungssuchendes Umherklicken in einer unverständlichen Umgebung empfunden wird, bedarf es der Anwendung verschiedener Methoden. Auf eine von ihnen möchte ich näher eingehen: die Entzerrung von Information durch Verlagerung auf Interaktionsebenen.
Betrachten wir das Diagramm in Abb. 4, das die Dimension „Offenheit“ des Nutzertyps „Reflektierter Profi“ zeigt wie es im Printbericht dargestellt ist. Dieses Diagramm wirkt durch die Linienverbindung der Werte ein wenig so, als sei es ein Polaritätsprofil / semantisches Differenzial dieses Nutzertyps. Problematisch ist dabei aus methodischer Sicht, dass in der Befragung keine Gegensatzpaare abgefragt wurden, sondern eine Lickert-Skala. Die der jeweiligen Aussage zustimmenden Probanden dieses Nutzertyps werden als Prozentsatz auf der x-Achse dargestellt, zusätzlich wird dieser Wert durch die Größe des Kreises visualisiert. Im Grunde genommen wäre hierfür ein Balkendiagramm die ausreichende Visualisierung.
Aus UX-Sicht weist dieses Diagramm ein Zuviel an textueller Information auf, das daher kommt, dass die abgefragte Aussagen vollständig auf der y-Achse wieder gegeben werden. Es gibt einen Hinweis darauf, dass die Autoren bzw. Layouter des Printberichtes das Problem der kognitiven Last erkannt haben: nämlich, dass sie versucht haben, durch Hervorhebung der Kernformulierung mittels fetten Schriftschnitts die Erfassbarkeit des Textinhaltes zu verbessern.

Abb. 4 — Diagramm im Printbericht: Zuviel textuelle Information verhindert schnelle Erfassbarkeit. [ 2, S. 25 ]
- Da ein Polaritätsprofil nur interessant ist, wenn zwei oder mehrere Objekte gleichzeitig dargestellt werden, entschied die Projektgruppe, die im Bericht dargestellten Informationen auf ihren Kern zu beschränken, indem keine Verbindungslinien zwischen den Werten gezogen werden, sondern diese lediglich durch Kreisgröße, numerischen Wert und Position auf einer y-Achse darzustellen.
- Als Maßnahme zur Informationsentzerrung wird auf die Darstellung der vollständigen Aussagen entlang einer Achse vollständig verzichtet. Stattdessen erhalten die Bubbles selbst ein Stichwort neben dem prominenten numerischen Wert. Die Darstellung der vollständigen Aussage wird also auf eine andere Modusebene verlagert, die durch Hovern des jeweiligen Kreises eingeblendet wird. Dieses ist vergleichbar dem Kniff, bei Charts ergänzende textuelle oder numerische Information in Tooltip-ähnliche GUI-Elemente zu verlagern, die nur dann sichtbar werden, wenn einzelne Datenpunkte gehovert werden.

Abb. 5 — Bubble-Diagramm statt Polaritätsprofil entzerrt Information.
Sehr elegant gestaltet ist die Transition zwischen den beiden Modi Hover/Normal: Wie bei einer realen Scheibe scheint sich die Bubble zu drehen, als ob sie an einem unsichtbaren Faden aufgehangen wäre, und zeigt ihre andere Seite.
Informationsdesign als mechanisches Ballett
Überhaupt: die Transitions! Die Art und Weise, wie Informationen in den Screen kommen, wie Screenelemente auf Hovern reagieren, das lebendige Pulsieren der Tag-Cloud, das Zusammenführen von Textenteilen, die sich während meines Scrollens sich zu kompletten Aussagen reißverschlussartig ergänzen, all das im richtig dimensionierten räumlichen und zeitlichen Maß – das ist schon gut inszeniertes mechanisches Ballett. Zwar nicht eines, das choreografiert ist für menschliche Körper. Aber eines, das choreografiert ist für Informationen, die sich schon irgendwie wesenhaft verhalten.
Die Art und Weise, wie sie von unten herbei huschen, über die Endposition hinaus schießen, leicht federn und dann ihre Position in der vertikalen Mitte des Screens einnehmen, um dann brav und rasend schnell auf die darzustellenden Ziffern hochzuzählen, hat etwas Magisches. Als Benutzer fühle mich dabei ein wenig wie ein Zauberer, der Informationen dazu veranlasst auf einer Bühne aufzutreten, mir ihre Geschichte zu erzählen und wieder abzutreten. Hier ein Recording von Interaktionen und Systemreaktion, das einen ersten Eindruck der Transitions vermittelt:
Webbasierte Animationen und Transitions sind vom Handwerklich-Technischen her betrachtet nichts aktuell Neues. Ihnen liegen JavaScript- und/oder CSS3-Libraries zugrunde. Trotzdem braucht es gute handwerklich Leistung und ein gutes Gefühl für die richtige Dimensionierung der Parameter des passend platzierten Effektes, so wie es in der vorliegenden Applikation im Großen und Ganzen auch zu finden ist.
Noch bemerkenswerter als die handwerkliche Leistung finde ich die Durchgängigkeit, mit der graphische Elemente und Texte in der Applikation animiert wurden. Dies deswegen, weil hier ein bisher gültiges Paradigma des Informationsdesigns gekippt wird, das lautete: Animation und Information schliessen sich in der Regel aus! So statuiert der Wikipedia-Eintrag Animation im Abschnitt Animation in der Lernpsychologie: „Animierte Bilder haben gegenüber statischen Repräsentationen den Vorteil, Veränderung explizit abbilden zu können. Sie stellen jedoch auch hohe Verarbeitungsanforderungen an die Lernenden. Daher sollten sie mit Bedacht eingesetzt und auf Sachverhalte beschränkt werden, die tatsächlich von einer bewegten Darstellung profitieren. Häufig werden jedoch selbst solche Medienbestandteile animiert und damit effekthascherisch überbetont, die dafür weitestgehend ungeeignet sind, wie zum Beispiel Texte.“ [3]
Ich denke, es ist an der Zeit, ein wenig hinter dieses Paradigma zu schauen und zu überlegen, ob dieses heute noch gültig ist. Es könnte sein, dass es sich bei der Behauptung der mangelnden Eignung animierter Information um einen Mythos handelt, der vor vielen Jahren in einem bestimmten Kontext nachgewiesen und publiziert wurde, seitdem weitergereicht wird und immer wieder erneut zitiert. Aber niemals empirisch unter aktuellen Bedingungen überprüft!
Animation = (funktionsloses) Ornament?
Animation – wenn ich dies höre, klingelt bei mir als Designer sofort die Alarmglocke. Bei diesem Wort befürchte ich das Gleiche wie der Autor des obigen Wikipedia-Zitates: Effekthascherei, Aufmerksamkeit ohne fundierte Inhalte, Ablenkung vom Wesentlichen, zu laut, zu bunt, zu viel! Dies geht gegen das Fokussierte, das Reduzierte, die klare Botschaft, das „Weniger ist mehr“, das so mühsam durch die Auseinandersetzung mit der visuellen Formwerdung der Inhalte erarbeitet werden muss. Welcher Designer kennt es nicht, wie oft eine visuelle Kommunikation im Entstehensprozess gesehen, assoziiert, umgestellt, gestrafft, reduziert werden muss, wie viele Ideen gestrichen werden müssen bis man an den klaren Kern kommt. Und dann kommt jemand mit überquellenden Powerpoint-Folien, bei denen Texte und Clipart-Grafiken auf die Folie wirbeln, zoomen und schachbrettern, was die Effektmaschine hergeben – es braucht ja nur einen Klick in die Animationsleiste. Formen, die keine Aussage treffen, sondern im schlimmsten Fall von der Inhaltslosigkeit der Aussagen ablenken sollen – das ist meine Furcht als Designer.
Als solcher weiss ich die Paradigmen des Funktionalismus zu schätzen. Einer dieser Leitsätze ist „Form follows function“ (Louis Sullivan). Die Gestaltung von Dingen soll sich aus der Funktion der Dinge ableiten. Andersherum gesagt: es soll nichts geben, was nicht eine Funktion unterstützt.
„Ornament ist vergeudete arbeitskraft und dadurch vergeudete gesundheit. So war es immer. Heute bedeutet es aber auch vergeudetes material, und beides bedeutet vergeudetes kapital.“ beschrieb Adolf Loos 1908 in seiner Schrift Ornament und Verbrechen, deren Titel designgeschichtlich einen weiteren Leitsatz des Funktionalismus zugespitzte. Sein Gedankengang: der Aufwand, der das Ornament erschafft, sei vergeudeter Aufwand, der besser dem Funktionalem dienen könne. Auf unser Thema übertragen führt dies zur Frage: ist die Animation ein zur Information hinzugefügtes Ornament, das eigentlich völlig überflüssig ist und nach dem Loos’schen Verständnis ebenfalls ein Verbrechen wäre?
Nun, der Begriff „Animation“ leitet sich aus dem Lateinischen „anima“ für Seele ab. Das Animierte ist das Beseelte, etwas das mit einer gewissen Autonomie agiert und reagiert. Aus diesem Blickwinkel könnte man sogar das System, mit dem der User interagiert, das die gewünschten Informationen bereitstellt und wieder wegnimmt und das auf Fehleingaben informierend antwortet, als beseeltes Wesen, als animiert betrachten. Man könnte nun den Standpunkt vertreten , es sei eigentlich nur konsequent, wenn die Informationen – genauer: Darstellungen (Text, Zahlen, Formen), die Informationen tragen – auch eine Art Eigenleben führen. Es wäre aber andererseits auch argumentierbar, dass es solche Ornamente gar erst nicht bedarf, da das Beseelte sich bereits im Verhalten des Systems ausdrücke.
Animierte Objekte in NUIs
Dass von Studenten Animationen im Informationsdesign ohne Scheu angewandt werden, mag einen ganz einfachen (Hinter-)Grund haben: sie sind in den vergangenen 10 Jahren groß geworden mit Geräten wie SmartPhone und Tablets. Diese Touch-Geräte sind in in einer neueren Phase der Hardware-Technologie entstanden und ihre Interfaces sind anders konzipiert als die der WIMP (Windows Mouse Pointer)-Systeme. Screeninhalte werden beispielsweise nicht gescrollt, sondern mittels Flick-Geste angeschubst; die Reaktion des Screeninhaltes auf die Geste entspricht demjenigen physischer Gegenstände: schnelle Bewegung am Anfang, danach allmähliches Verlangsamen. Diese sich über einen Zeitraum verändernde visuelle Reaktion des Screeninhaltes ist ebenfalls eine Animation – aus technischer Sicht wie aus Nutzersicht. Und sie hat eine Funktion, nämlich das steuerbare „Scrollen“ des Screeninhaltes.
Ein anderes Beispiel für eine funktionale Animation ist der Federeffekt im iOS 7: Gelangt der User beim Scrollen eines Inhaltes mittels Swipe oder Flick-Geste an dessen Anfang oder Ende, so wird diese Begrenzung deutlich, indem der Inhalt zwar über diese Begrenzung hinaus läuft, aber sofort wieder an die Begrenzung zurückfedert. Der Screeninhalt vollzieht eine nicht-lineare Bewegung, die autonom abläuft und so aussieht, als sei dieser Inhalt ein physikalisches Objekt, das mittels einer unsichtbaren Feder mit dem Rand des Screens verbunden – also eine Animation. Das System gibt also keinen textuellen Warnhinweis (z.B. „Sie können nicht weiterscrollen“) oder graphische Warnung (z.B. rotes Warndreieck-Icon am Ende der Scrollbar) an den Nutzer aus. Vielmehr versteht der Nutzer die Aussage einzig des Systems anhand des Verhaltens der Elemente, eben der Art und Weise, wie diese animiert sind. Deswegen werden diese Interfaces eben auch „natural“ genannt, da sie sich anfühlen wie das, was wir aus unserer physischen, natürlichen Umgebung kennen.
Die NUIs sind bereits seit einiger Zeit Leitmedium geworden; sie produzieren neue Standards bezüglich Look und Feel von Benutzungsoberflächen. Und damit kommt auch die Nutzererwartung, dass sich auch die Objekte in Webmedien mehr wie natürliche Objekte verhalten sollen. Und unter diesem Blickwinkel stellt sich mir die Frage: Was wirkt natürlicher – Texte, die auf einer Screenfläche bereits vorhanden sind wie bei einem bedrucktem Blatt Papier? Oder Texte, die beim Scrollen von ausserhalb zusammenkommen und sich auf der Fläche positionieren? Ehrlich gesagt: auf mich wirkt zweites natürlicher – und spannungsvoller erst recht.
Ich denke: im Zeitalter von NUIs ist es wichtig, den Gestaltungselementen Lebendigkeit und Beseeltheit mitzugeben. Und dies selbstverständlich nicht als inhaltsleere Effekthascherei, sondern zur Optimierung von Steuerbarkeit von Controls und inhaltlicher Aussage des inhaltlich Kommunizierten.
Kinetic Type
Die klassische Form, ja sozusagen die reinste Form, von Information ist der Text. Der Text gilt als Verkörperung des Satzes, der wiederum versprachlichter Gedanke ist. Es gibt sogar Menschen, die für sich ausschließlich nur geschriebenen Text oder gesprochenes Wort als Information zulassen und ausschließlich Zeitungen mit möglichst geringem Bildanteil lesen. TV oder das Genre der Illustrierten werden in der Wertewelt dieser Menschen nicht als Informationsmedium akzeptiert.
Nun, solche Sichtweisen würde der Mediengestalter von heute eher als Haltung einer Randgruppe von Sonderlingen einordnen. Nichtsdestotrotz ist das Konzept der starren Typografie auch heute noch ein wirkendes Paradigma in der Mediengestaltung, das optimale Effizienz und Effektivität beim Aufnehmen und Verstehen der durch Texte vermittelten Informationen verspricht. In unserer Vorstellung hat ein Text gefälligst starr zu sein und an derselben Stelle zu stehen, damit wir ihn optimal erfassen können. Der menschliche Wahrnehmungsvorgang mit seinen Fixationen und Sakkaden [5] legt die Ansicht ja nahe: das Lesen von Text ist ein eigentlich mühsamer und mit Fehlern behafteter Vorgang, der keine weitere Komplikation durch tanzende Buchstaben, vibrierende Wörter und die Position verändernde Zeilen gebrauchen kann.
Trotzdem ist die Frage, ob in einem Informationsdesign, bei dem Text kein romanhafter Fließtext, sondern oft nur ein Informationsträgern in einem Medienmix ist, die Frage nach der Leseeffizienz eine wesentliche Fragestellung. Würde ein animierter Text tatsächlich schlecht lesbar wegen unerträglich hoher kognitiver Last, so könnten viele Filmabspänne, Sende-Trailer, TV-Werbespots und Werbung auf Bussen und LKWs gar nicht funktionieren.
Ich halte nichts von Antworten mit Ja oder Nein, wenn es um den Frage nach dem Einsatz von animierter Schrift geht. Ich denke vielmehr, die Antwort liegt in der Suche nach dem richtigen Maß innerhalb einer bestimmten Kommunikationsaufgabe; handwerklich gesprochen also um die richtige Adjustierung der Parameter, damit Text animiert wird und trotzdem lesbar ist. Und erst ein User Research, der Effizienz und Effektivität des Verstehens eines solchermaßen animierten Texte mit einem nicht-animierten Text misst und vergleicht, würde fundiert darauf hinweisen, ob und unter welchen Umständen animierter Text schlechter zu lesen, zu verstehen und zu erinnern ist als der nicht-animierte. Bisher habe ich keine aktuelle Untersuchung hierzu gesehen.
2011/12 wurde in Mainz erstmalig die Ausstellung „Moving Types“ gezeigt, die die bewegte Schrift in der Geschichte und in den verschiedensten Anwendungen zum Thema hat [6]. Die Ausstellung vermittelt an über 200 Beispielen bewegter Typografie, dass Schrift in Bewegung nichts so Ungewöhnliches ist. Die Ausstellung macht deutlich: nicht nur die klassischen Attribute von Text wie Schriftart, Schriftgröße, Zeilenabstand tragen zur guten Gestaltung und zur Kommunikation bei, sondern auch Attribute, mit denen Schrift animiert werden kann.
Darüber hinaus gibt es aber auch seit einigen Jahren visuelle Kommunikation, bei denen Text der lebendige Hauptakteur eines Textes gemacht wird. Eine Fundstätte für staunenswerte Werke ist (wieder einmal) Youtube; finden lassen sich Beispiele mittels Suchbegriffe wie „Typographic Animation“, „Type in motion“ oder „Kinetic Type“. Oft werden Songtexte mit animierter Typo dargestellt und folgen der Musik wie bei Mad world by Gary Jules. Oder der Text kombiniert thematisch assoziative Begriffe in animierter Form mit ikonenhaften Grafiken. Mein persönlicher Favorit ist ein Movie, das nicht mehr künstlerisches Experiment animierten Textes ist, sondern bereits ein ausgereiftes informationsdesignerisches Werk ist: Eine Textanimation mit Informationen zur Nutzung von Zuckerrohr für Nahrungsmittel und zur Energiegewinnung. Bitte anschauen – danach wird man differenzierter die Frage beantworten: Schliessen sich animierter Text und Informationsdesign aus?
Ob und inwieweit das in dieser Form Gesehene und Gelesene Verständnis und Wissen schafft und ob dieses Wissen auch nachhaltig besser erinnert werden kann als in einer mehr statisch präsentierten Form – das wäre ein Thema, das zukünftig im Zuge einer User Research-Studie untersucht werden könnte.
Quellen
[1] Arweiler, Janus, Kirchner, Leutner: Nutzertypen in Deutschland 2014, Arbeit im Rahmen der Lehrveranstaltung Multimediales Informationsdesign 2014/15, Fachbereich Online Medien an der DHBW Mosbach.
[2] Initiative D21 e.V., TNS Infratest (Hrsg.): D-21-Digital-Index 2014
[3] Wikipedia-Artikel Animation, Abschnitt Animation in der Lernpsychologie. Zuletzt aufgerufen 31.04.2015.
[4] Loos, Adolf (1908): Ornament und Verbrechen
[5] Lotz, Kaselow (2007): Ich sehe das, was du grad siehst – Der Eyetracker
[6] Ludwig, Annette et al. (Hrsg.): Moving Types – Lettern in Bewegung, Medienausstellung und Katalog (1.Auflage, Mainz 2011).
[7] Aloe Design Studios (2011): Kinetic Type Animiation for Unica Brazil and sugarcane.org (movie)
Abstract
Usability Engineers und UX Researcher werden mit der Erwartung konfrontiert, auch bei kleinen Fallzahlen nicht nur qualitative, sondern auch quantitative Ergebnisse zu liefern. Hier hilft das aus der Statistik bekannte Konstrukt des Konfidenzintervalls, das die korrekte Verallgemeinerung von in Stichproben-Tests oder durch Logfiles ermittelten Parametern auf diejenigen der Population erlaubt.
Im Artikel wird anhand von Fallbeispielen dargelegt, wie die Konfidenzgrenzen zum Mittelwert der Zielerreichung ermittelt werden und wie die quantitative Interpretation einer Bewertung zweier Naming-Alternativen durch Probanden eines Usability-Testes erfolgt.
1 Nur Tendenzen…?
UX Researcher, die im Bereich Usability tätig sind, kennen das Problem: Ergebnisse aus im Labor durchgeführten Tests werden vom Product Owner oder Management als nicht verallgemeinerbar angezweifelt. Der Zweifel: da es bei den für Labortest typischen geringen Probandenzahlen sehr gut möglich sei, dass einige wenige Individuen aufgrund von Fähigkeiten, Vorlieben, Kenntnissen, Interessenlagen die Ergebnisse so stark beeinflussen (in der Statistik-Sprache „verzerren“), könne von den im Test gewonnenen quantitativen Ergebnissen nicht auf die gesamte Nutzergruppe geschlossen werden. Auch sorgfältigstes Screening der Probanden und deren repräsentative Zusammensetzung nach Zielgruppen kann den Verweis auf die geringe Stichproben-Zahl nicht entkräften.
Ergänzend zu diesen Zweifeln ist mir in den vergangenen Jahren eine ähnliche skeptische Sichtweise auch bei einigen Marktforschungsabteilungen und Usability-Laboren begegnet, die sowohl im Gespräch als auch im Ergebnisbericht vor der Verallgemeinerung von ermittelten quantitativen Kennzahlen warnten und betonten, dass die gewonnenen Ergebnisse immer nur Tendenzen seien!

Abb. 1: Aus einem Ergebnisbericht eines Usability-Labors: Warnung vor Schlüssen aus quantitativen Ergebnissen bei n=20.
Diese vorsichtige und mahnende Haltung ist wohl auch eine Reaktion auf den gerade im Management verbreiteten – und durchaus nachvollziehbaren – Wunsch, harte „facts and figures“ als Bewertungs-, Entscheidungs- und Argumentationsgrundlage verfügbar zu haben. Aber durch die ständige Mahnung der Researcher, die gewonnenen Ergebnisse seien nicht quantitativ verallgemeinerbar, manövrieren die Researcher allerdings sich selbst und ihre Ergebnisse in eine defensive Ecke, in der sie Gefahr laufen, an Argumentationskraft und Wertschätzung für ihre Untersuchungsergebnisse zu verlieren.
… oder geht es auch genauer?
Unnötigerweise! – muss ich an dieser Stelle hinzufügen. Denn die Statistik liefert dem UX Research die Begriffe, Methoden und Tools nicht nur für große Fallzahlen, sondern auch für die bei Labortests typischen kleinen Fallzahlen. Meine eigenen Usabilitytests hatten Teilnehmerzahlen zwischen 8 und 22 und ich kenne Kollegen, die viele Tests mit weniger als 10 Teilnehmern durchführen müssen. Jedenfalls liegt der typische Usability-Test im Labor deutlich unter n=30, was in der Statistik die magische Grenze für die Anwendung verschiedener Gesetzmäßigkeiten und Formeln ist. Aber auch für n < 30 hat die Statistik ausreichend Methoden und Formeln bereit, um klare Aussagen zur Verallgemeinerbarkeit der durch die Testteilnehmer erhaltenen quantitativen Daten auf die Population treffen zu können.
Auch in der – bislang sehr spärlichen – Literatur zu quantitativen Ergebnissen des UX Researchs wird betont, dass – entgegen der allgemein verbreiteten Ansicht – auch bei geringen Fallzahlen quantitative Datenanalysen und valide statistische Aussagen getroffen werden können: „There is an incorrect perception that sample sizes must be large to use statistics and interpret quantitative data … Don’t let the size of your sample (even if you have as few as 2 – 5 users) preclude you from using statistics to quantify your data and inform your design decisions.“ (Sauro & Lewis 2012, S. 10)
Zusätzlich müssen wir uns im UX Research darauf einrichten, dass unsere Auftraggeber über qualitative Ergebnisse hinaus quantifizierbare Ergebnisse zunehmend erwarten: „Quantitative usability data are becoming an industry expectation.“ (Molich, R. et al 2009, S.9)

2 Fallstudie Naming Alternativen
Im Jahre 2010 ließen wir zwei Varianten einer webbasierten Suche auf Usability und Akzeptanz testen. Zweck der Applikation ist, dass die Nutzer deutschlandweit sich zu einem (einzugebenen) Ort innerhalb Deutschland die nächstliegenden Standorttypen (Filiale, Briefkasten, Packstation usw) des Logistik-Unternehmens anzeigen lassen können und zu jedem einzelnen Standorttypen weitere Detailinformationen wie Öffnungszeit, Leistungsspektrum, Adresse etc. erhalten.
Ein (sehr kleiner) Teil des Usability-Testes bestand darin, zu ermitteln, welcher Begriff die folgende Zeitbestimmung am griffigsten und am verständlichsten wiedergibt: Vor allem Geschäftskunden, die ihre Briefe und Pakete (in der Logistik-Sprache als „Sendungen“ bezeichnet) gesammelt in einer Filiale abgeben, interessiert der Zeitpunkt, bis zu dem garantiert ist, dass die abgegebenen Sendungen noch am selben Tag aus der Filiale heraus weiter befördert werden. In der Offline-Welt der Logistik gab es für diesen Termin bis dahin den seit vielen Jahren verwendeten Begriff „Annahmeschluss“. Als – aus konzeptioneller Sicht treffendere – Alternative wurde „Versandschluss“ ins Spiel gebracht. Für beide Begriffe gab es aus unserer internen Sicht Pros und Cons. Aber welcher der beiden Begriffe wäre für die Nutzer der Suchapplikation unterm Strich verständlicher und passender? Und gäbe es einen deutlichen quantitative Unterschied in der Präferenz?
Wir ließen die Probanden nach Präferenz und Gründen in Einzelgesprächen telefonisch kurz befragen. n = 20, Privatkunden und Geschäftskunden, Nutzer und (bisherige) Nicht-Nutzer der Applikation. Alle Probanden waren potentielle Nutzer. Das Ergebnis: 7 pro „Annahmeschluss“, 13 pro „Versandschluss“.

Abb. 2: Umfrage im Usabilitytest zur Präferenz zweier Naming-Alternativen: klare Präferenz für „Versandschluss“ – aber was schließt man daraus für die Population aller Nutzer?
Die Probanden nannten als Gründe zu ihrer jeweiligen Präferenz:
Pro „Versandschluss“:
- Versandschluss ist verständlicher, weil klar ausgedrückt wird, das eine Sendung nicht nur angenommen, sondern auch verschickt wird. „Versandschluss zeigt mir klar, dass die Post bis zu diesem Zeitpunkt versendet wird.“ (O-Ton w/GK)
- für Normalverbraucher leicht zu merken.
Pro „Annahmeschluss“:
- Begriff ist bereits bekannt und geläufig (gilt für diejenigen, die die spezifische Bedeutung im Kontext von Geschäftspost kennen)
Die Mehrheitsverhältnisse waren deutlich und so entschieden wir, in der Applikation künftig den Begriff „Versandschluss“ zu verwenden. Für die Entscheidung war auch relevant, dass alle 3 befragten Geschäftskunden – also solche User, die am ehesten von dem Informations-Feature betroffen sind – für „Versandschluss“ waren.
Punktschätzung für die Population
Betrachten wir nun, inwieweit die aus der Befragung gewonnenen Daten verallgemeinert werden können. Aus statistischer Sicht handelt es sich bei der Befragung der 20 Probanden um eine Stichprobe, von der aus auf die Population aller potenziellen Nutzer der Applikation geschlossen wird. Die gewonnenen Daten sind diskret-binär, da die Präferenz für den einen Begriff gleichzeitig die Ablehnung des anderen Begriffs bedeutet; die Daten verhalten sich wie Daten zur Aufgabenerfüllung (erfüllt – nicht erfüllt) oder wie beim Münzwurf (Erfolg – Misserfolg).
Sauro & Lewis machen den zur Punktschätzung verwendete Algorithmus nicht nur von der Fallzahl, sondern auch von der Größenordnung der Erfolgsrate abhängig. Eine Untersuchung zu den verschiedenen Rechenverfahren und ihre Tauglichkeit zur Punktschätzung siehe Sauro & Lewis 2012.
Im vorliegenden Fall (n = 20, und 0,5 < p(x) < 0,9) ist der beste Punktschätzer die Erfolgsrate der Stichprobe ohne Korrektur (Sauro & Lewis 2010, S.25). Mit den Werten aus der Befragung (x = 13, n = 20) erhalten wir 0,65. 65% aller Nutzer werden also „Versandschluss“ besser finden als „Annahmeschluss“ – so die Schlussfolgerung. Der wahre Wert wird allerdings daneben liegen. Wie weit er daneben und innerhalb welcher Spanne er um 65% streuen kann, bestimmen wir mit dem Konfidenzintervall.
Das Konfidenzintervall
Vereinfacht gesagt, kennzeichnet das Konfidenzintervall denjenigen Bereich, innerhalb dessen der Parameter der Population sich befinden kann – auf der Grundlage einer gegebenen Wahrscheinlichkeit (genannt „Konfidenzniveau“). Standardmäßig wird ein Konfidenzniveau von 95% angesetzt. Andersherum betrachtet: das Konfidenzintervall zeigt, wo der Populationsparameter sich höchstwahrscheinlich NICHT befinden wird. Da das Konfidenzintervall die Stichprobengröße in seinen Wert mit einbezieht, enthält es Informationen zur Präzision der Schätzung, die wir aus den Stichprobendaten vornehmen – große Stichproben führen zu einem schmalen Intervall, kleine Stichproben zu einem breiten.
Die Grenzen eines Konfidenzintervall für binomiale Daten werden mittels Wald-Verfahren berechnet (Lewis & Sauro 2012, S. 23)

Formel 1: Konfidenzintervall für binomiale Daten mittels Wald-Verfahren
Im vorliegenden Fall wollen wir ein Konfidenzniveau von 95%, der entsprechende kritische Wert beträgt 1,96. Daraus ergeben sich für das Konfidenzintervall folgende gerundete Werte:
Untere Grenze: 0,65 – 0,21 = 0,44.
Obere Grenze: 0,65 + 0,21 = 0,86

Abb. 3: Geschätzter Mittelwert und Konfidenzintervallgrenzen (Konfidenzniveau 95%) für Präferenz des Begriffs „Versandschluss“. Berechnung mittels Wald-Verfahren. Die unterhalb der Kurve gefüllte blaue Fläche zeigt die Wahrscheinlichkeitsdichte von 95%; die beiden ausserhalb liegenden kleinen weissen Fläche repräsentieren jeweils 2,5% .
Wir können jetzt folgende Aussage zusätzlich zur geschätzten Erfolgsquote von 65% treffen: mit 95%er Wahrscheinlichkeit liegt der Anteil derjenigen User, die „Versandschluss“ besser finden zwischen 44 und 86%. (Ich gehe an dieser Stelle nicht darauf ein, ob die Aussage über die Realität oder über das Verfahren getroffen wird.)
Adjusted Wald-Verfahren
Lewis und Sauro haben nachgewiesen, dass für kleine Stichprobenumfänge das Wald-Verfahren zu ungenau ist (Lewis & Sauro 2012, S. 21). Zu empfehlen ist das adjustierte Wald-Verfahren, das für kleine Stichproben treffendere Ergebnisse liefert. Hierzu wird im Zwischenschritt ein adjustierte Punktschätzer ermittelt. Einen gut angenäherten Wert für 95% Konfidenzniveaus erhalten wir, indem zwei Erfolge und zwei Misserfolge hinzuzählen. Dieser angepasster Punktschätzer wird in die Wald-Formel eingesetzt, mit der das adjustierte Konfidenzintervall berechnet wird.

Formel 2: Konfidenzintervall für binomiale Daten mittels adjustiertem Wald-Verfahren für geringe Stichprobenumfänge
Adjustierter Punktschätzer p_adj = 15/24 = 0,625 – Untere Grenze: 0,625-0,194 = 0,431 – Obere Grenze: 0,625+0,194 = 0,819
Nach dem angepassten Wald-Verfahren können wir folgende zusammen gehörenden Schlussfolgerungen aus unserem Test ziehen: Der Anteil der Nutzer (aus der Grundgesamtheit, nicht derjenigen aus dem Usabilitytest), die „Versandschluss“ besser finden, liegt mit 95%iger Wahrscheinlichkeit zwischen 43 und 82%. Der geschätzte Punkt des Mittelwertes liegt bei 62,5%.

Abb. 4: Konfidenzintervalle und Punktschätzer für Präferenz zweier Naming-Alternativen, Konfidenzniveau 95%, Datenerhebung: Befragung innerhalb Usabilitytest mit n = 20, Berechnung: Adjusted Wald-Verfahren
Der Nutzen für den UX Researcher
Nun mag es übertrieben erscheinen, wenn im vorliegenden Fall zweier Alternativen, bei dem doppelt so viele Teilnehmer für eine Alternative gestimmt haben wie für die andere, Punktschätzungen vorgenommen werden und Konfidenzintervalle bestimmt werden. Die Alternativen sind ja klar und einfach und die Mehrheitsverhältnisse in der Stichprobe evident, so dass die Entscheidung zwischen beiden Alternativen offensichtlich und zwingend ist. Wozu also einem Entscheider, der die Dinge in der Regel eher einfach als wissenschaftlich korrekt erklärt haben will, mit Punktschätzern und Konfidenzintervallen kommen, wenn in der Stichprobe alles klar zu sein scheint?
Nun – um beim Entscheider auf den sachlich richtigen Punkt zu kommen. Statt wie bislang zu sagen: „Die Tendenz ist, dass mehr User „Versandschluss“ treffender als „Annahmeschluss“ finden.“ können wir nunmehr sagen: „Mit 95%iger Wahrscheinlichkeit liegt der Anteil derjenigen Nutzer, die „Versandschluss“ besser finden, zwischen 43 und 83% mit der größten Wahrscheinlichkeit bei 62,5%. Die geschätzte Anteil derjenigen, die Annahmeschluss bevorzugen, beträgt dagegen lediglich 37,5%, ebenfalls mit einer Toleranz von ±20% bei einer 95% igen Wahrscheinlichkeit.“ Die Empfehlung des UX Researchers ist in beiden Situationen die gleiche („Implementiere Versandschluss“), die zweite Begründung ist aber präziser und mit „hard figures“ hinterlegt.
Die Wege des quantitativen UX Research sind nicht immer intuitiv. Was wäre die intuitive Schlussfolgerung für die Aufgabenerfüllungsrate, wenn in einem Usability-Test 10 von 10 Probanden die Aufgabe erfüllt haben? Nun…? Die richtige Antwort lautet: 92% (nach Laplace-Verfahren (x+1)/(n+2) = 11/12=0,9167 (Lewis & Sauro 2012, S. 25). Und die untere Grenze des zugehörigen Konfidenzintervalls auf dem 95%-Niveau beläuft sich immerhin noch auf 77% ! Diese Informationen sind deutlich schärfer als eine Warnung „Dies ist nur eine Tendenz“ und präzisieren unsere Vorstellungen über die Welt ausserhalb des Usability-Testes.
Und genau deswegen gilt es, sauber und sachgerecht zu argumentieren. Die Konfidenzintervalle erlauben uns einzuschätzen, wie gut / wie präzise die KPI-Werte sind, die wir von den Stichprobendaten auf die Population übertragen. Denn die KPIs der Population sind ja das, was letztlich interessiert. Konfidenz-Intervalle beziehen die Komponente der Stichprobengröße in ihre Aussage mit ein: Je größer unsere Stichprobe, je größer also n, desto kleiner wird die Unsicherheit und desto kleiner ist das Intervall für ein gewähltes Konfidenzniveau.
Online-Helferlein
Es ist nicht notwendig, die Rechnungen für den Punktschätzer und das Konfidenzintervall selber durchzuführen: Jeff Sauro stellt auf seiner Website einen webbasierten Kalkulator für verschiedene Berechnungsverfahren zur Verfügung. Dabei sind auch unterschiedliche Konfidenzniveaus möglich. Der Kalkulator ist auf die Berechnung der für UX wichtigen Metrik <Anzahl der erfüllten Aufgaben> ausgelegt; man kann mit ihm jedoch auch andere binäre Daten ermitteln. Sehr hilfreich sind ebenfalls die dort vorhandenen Hinweise, unter welchen Randbedingungen welches Verfahren genutzt werden sollte.
3 Fallbeispiel Messung der Zielerreichung bei einer webbasierten Umkreissuche
In der Definition von Usability ( = Gebrauchstauglichkeit) in der Norm ISO 9241, Teil 210, werden drei Leitkriterien bestimmt, die eine Quantifizierung von Usability erlauben:
- Effektivität: „Vollständigkeit und Genauigkeit der Zielerreichung“
- Effizienz: „zur (effektiven) Aufgabenerfüllung benötigter Aufwand“
- Zufriedenstellung: „Freiheit von Beeinträchtigung und positive Grundeinstellung zum Produkt“
Definition von Usability nach DIN ISO 9241, Teil 210. Zum besseren Verständnis visuell strukturiert.
Ich betrachte innerhalb dieses Artikels über Konfidenzintervalle ausschließlich das Kriterium der Effektivität anhand des Fallbeispiels derselben Suchapplikation wie zuvor.
Das Erreichen eines festgelegten Zieles ist in Usability-Testing eine wesentliches Kriterium: können User mittels der benutzten Software nicht die vorgesehenen oder beabsichtigten Aufgaben / Ziele erreichen, so gilt die Software als nicht benutzbar.
Im laborgestützten Usability-Test von Software/ Websites wird die Aufgabenerfüllung in der Regel durch die Testleiter nach festgelegten Kriterien in den einzelnen Abschnitten bejaht oder verneint. Sind mehrere Probanden nicht in der Lage, eine bestimmte Aufgabe zu erfüllen, so wird der entsprechende Teil der Software mit der höchste Prioritätsstufe für notwendige Verbesserungen bewertet.
Im vorliegenden Fallbeispiel des User Feedbacks zur Suchapplikation ging es mir darum, einen Key Performance Indicator für eine webbasierte Suche über einen langen Zeitraum verfügbar zu haben, der die Effektivität der oben bereits genannten Umkreissuche misst. Diese Suche erstreckt sich auf alle Standorte und Standorttypen eines Logistik-Unternehmens, das in ganz Deutschland operiert.
Untersuchte Applikation:
Zweck der untersuchten Applikation ist, dass die Nutzer deutschlandweit sich zu einem (einzugebenen) Ort innerhalb Deutschland die nächstliegenden Standorttypen (Filiale, Briefkasten, Packstation usw) anzeigen und zu jedem einzelnen Standorttypen weitere Detailinformationen wie Öffnungszeit, Leistungsspektrum, Adresse etc. darstellen lassen können. Typischerweise muss der Nutzer ein bis drei Bedienschritte durchlaufen, bis er die Detailinformationen erhält: Aufruf der Applikation -> Eingabe des eigenen Standortes, ggf. mit zusätzlichen Filtern -> Auswahl aus Suchergebnissen -> Detailinformationen
Methode:
Die Nutzer erhielten unterhalb der Suchergebnisse einen Kasten „Kurzbewertung“ mit der Frage „Haben Sie die von Ihnen gesuchten Informationen gefunden?“ Die Antwortmöglichkeiten waren „ja“ oder „nein“. Wurde einer der Radiobuttons angeklickt, so konnten zusätzliche Informationen in ein Freitextfeld eingegeben werden, bevor die Antwort an den Server gesendet wurde. Um die Teilnahmehürde möglichst gering zu halten, wurde auf weitere differenzierende Fragen verzichtet. Uns war wichtig, den Nutzungsprozess der Suche in ihren verschiedenen Schritten nicht durch die Umfrage zu stören, sondern diese als „nicht-invasiven“ Feedback-Kanal zu positionieren.
Daher wurde darauf verzichtet, durch Animationen, Gestaltung als Popup oder ähnliche aufmerksamkeitsfordernde Maßnahmen den Kurzbewertungs-Kasten dem Nutzer aufzudrängen.
Abb. 6: Suchergebnis mit anhängender Bewertung der Applikation (links unten) durch den User.
Wir müssen „im Feld“ es dem einzelnen Nutzer es überlassen, zu definieren, ob er seine Ziele erreicht hat, da nur er diese kennt. Es ist nicht ganz auszuschließen, dass einzelne Nutzer Informationen suchen, die die Umkreissuche weder bieten kann noch soll. Jedoch wissen wir aus mit der Umkreissuche durchgeführten Usability-Tests, dass in aller Regel Nutzer den eigenständigen Charakter der Standortsuche erkennen und auch entsprechend abgrenzbare Erwartungen an die von dieser Suche gelieferten Informationen haben.
Die gelieferten Ergebnisse sind in folgender Weise interpretierbar: Die Summe aller Ja und Nein-Antworten liefert uns die Stichprobenanzahl n. Die Summe x aller Ja-Antworten ist die Teilmenge derjenigen Nutzer, die die gesuchten Informationen mittels der Such-Applikation erhalten hatten, d.h. sein Ziel erreichen konnte. Auf der Rohdaten-Ebene haben wir also binäre Daten.
Um sinnvolle Muster erkennen zu können, aggregiere ich die Daten auf Tagesebene; ich betrachte also jeden Tag eine Stichprobe von Nutzern n, die Feedback gegeben haben. Darüber gibt es eine Anzahl von Nutzern, die ihr Informationsziel erreicht haben. Die beiden Werte werden auf der Primärachse aufgetragen. Der Quotient beider Werte bezeichnet den entsprechenden Anteil (in %); der Wert wird auf der Sekundärachse aufgetragen. Ebenso werden die zur jeweiligen Stichprobe errechneten Konfidenzgrenzen zum genannten Wert dargestellt.
Einschränkung: Die beschriebene Meßmethode mit der „nicht-invasiven“ Feedback-Platzierung lässt diejenigen Nutzer aussen vor, die auf dem Weg zur Zielerreichung scheitern oder abbrechen, also nicht bis zum Schritt der Suchergebnisse vordringen können, und daher keine Möglichkeit haben, ihr Feedback in die Kurzbewertung einzubringen. Das aus den Daten gewonnene Ergebnis x ist streng genommen zu verstehen als „x% der Nutzer haben bei der Umkreissuche ihr Ziel erreicht, abzüglich des unbekannten Prozentsatzes derjenigen, die gescheitert sind oder abgebrochen haben“. In der Diskussion zur Methodik der Quantifizierung von Software-Effizienz gibt es eine ähnliche Diskussion darüber, ob die Zeiten von abgebrochenen oder falsch gelösten Aufgaben in die auszuwertenden Daten mit einfließen oder außen vor bleiben. Hierzu hat Bernard Rummel auf der Konferenz „Mensch und Computer 2014“ ein ausführliches Tutorial gehalten (Rummel, B. 2014)

Abb. 7: Zielerreichung in webbasierter Umkreissuche (Vergrösserte Darstellung mittels Klicken)
Die Daten wurden vom 1. März bis zum 22.Oktober des Folgejahres erhoben, insgesamt 600 Tage. Bei starker Schwankung der Teilnehmerzahlen an der Umfrage (Mittelwert (n) = 163,4 – Standardabweichung σ(n) = 45,1 – Variationskoeffizient V(n) = 27,2%) ist der Zielerreichungsanteil im wesentlichen konstant: Mittelwert (z) = 0,769 – Standardabweichung σ(z) = 4,8 – Variationskoeffizient V(z) = 6,3%.
Muster der Teilnehmerzahl
Betrachten wir den Graphen der Teilnehmerzahl, so können anhand der erkannten Muster mit Blick auf die zugrundeliegenden Rohdaten einige Aussagen treffen:
Die Schwankungen in der Teilnehmerzahl korrelieren mit bereits bekannten Nutzungsfrequenz-Mustern der Dienstleistungen des Unternehmens:
- Die Wochentage bilden eine starke saisonale Komponente. Dabei werden die Dienstleistungen an den Werktagen stark frequentiert; am Wochenende deutlich weniger. Dies führt im Graphen zur Gruppenbildung der Strichsäulen im gleichmäßigen Rhythmus.
- An den in Deutschland wichtigsten Feiertagen wie Ostern, Weihnachten und Sylvester geht die Teilnehmerzahl sehr stark zurück, stellenweise bis auf Null. Die entsprechenden Stellen in den Graphen wirken wie Ausreisser; sie sind aber nicht in der Qualität der Umkreissuche begründet.
- Im Herbst steigt die Häufigkeit der Teilnahme allmählich immer weiter an und erreicht ihr Maximum kurz vor den Weihnachtstagen.
Die diesen Mustern zugrundeliegende Nutzungsfrequenzen sind auch aus dem Offline-Geschäft des Logistik-Unternehmens bekannt. Eine detailiertere Analyse wäre aufgrund dieser Datenlage möglich; ist aber nicht Gegenstand dieses Artikels.
Muster der relativen Zielerreichung
Die relative Zielerreichung bewegt sich über den gesamten Zeitraum auf hohem Niveau von im Mittel knapp 77%. Fast 4 von 5 Teilnehmern haben nach ihrer eigenen Einschätzung die gesuchten Informationen erhalten und damit ihr Ziel erreicht. Zur über den gesamten Zeitraum von 600 Tagen hinweg relativ konstanten Zielerreichungsquote passt, dass während des Datenerhebungszeitraumes die Applikation keine wesentliche Veränderung in der Benutzerführung, dem Pageflow oder der Funktionalität stattfand; es wurden lediglich ständig Aktualisierungen in dem der Applikation zugrundeliegenden Datenbestand vorgenommen. Ich persönlich finde die Stabilität der Zielerreichungsquote über solch einen langen Zeitraum bemerkenswert; die Werte dieser Langzeitbeobachtung zeigt auch, dass kürzere Beobachtungszeiträume ebenfalls zuverlässige Daten liefern können, wenn nicht neu hinzukommende Variablen die Systemperformanz stören.
Ausreisser der relativen Zielerreichung
Aufgrund der vorhandenen Konstanz über den Beobachtungszeitraum sind die wenigen Ausreisser um so auffälliger:
| Datum | Teilnehmerzahl n | Zielerreichungsquote Z | Tag |
| 19.04. 2011 | 260 | 51% | Dienstag vor Ostern |
| 22.04.2011 | 101 | 57% | Karfreitag |
| 13.06.2011 | 129 | 60% | Pfingstmontag |
| 24.12.2011 | 84 | 56% | Heiligabend |
| 22.04.2012 | 12 | 100% | Sonntag |
| 23.06.2012 | 21 | 38% | Samstag |
Tabelle 1: Ausreisser und zeitliche Lage der zugehörigen Tage.
Meine hypothetische Erklärung für die ersten 4 Ausreisser ist, dass vor den wichtigen und oftmals mit Urlaub verbundenen Feiertagen die noch zu erledigende Post Stress und Belastung beim Nutzer auslöst und damit verbunden die Ungeduld steigt und die Toleranzschwelle sinkt. Die Ausreisser bilden gewissermaßen einen Nervositätsausschlag der Nutzer ab.
Das Positive aus Sicht des Product Owners (und des UX Designers) ist, dass diese die Performanz der Applikation senkenden Ursachen ausserhalb der Applikation liegen. Bei dieser Interpretation gehen wir von aussergewöhnliche Belastungen von außen aus, die auf die Usability-Performanz durchschlagen. Dabei verstehen wir die Feiertage als ein Faktor des in der o.g. Usability-Definition genannten „konkreten Nutzungskontext“. Wäre das zu evaluierende System eines, das unfallkritisch ist (z.B. System zur Ampelregelung), so müsste das System dringend robuster gebaut werden – in diesem Fall würde man aber als Usability Engineer ohnehin eine Zielerreichungsquote von 77% niemals akzeptieren.
Den vorletzten (positiven) Aussreisser mit 100% Zielerreichungsquote erkläre ich mir durch – Zufall. In diesem Fall nahmen nur sehr wenige Nutzer an der Bewertung teil und zufälligerweise erhielten (!) alle 12 die gesuchten Informationen. Die Wahrscheinlichkeitslehre sagt uns, dass in einer langen Beobachtungsreihe irgendwann auch diese Konstellation mal vorkommen muss.
Gleiches, nur mit gegenteiligem Vorzeichen, gilt für den letzten Ausreisser, bei dem die geringe Teilnehmerzahl und die zufällige geringe Zielerreichungsquote von 38% zu einem Ausreisser nach unten führt. Mögliche Ursachen sind systemeigene wie z.B. ein zeitweiser Ausfall der Datenbank, oder auch der reine Zufall, dass 8 Nutzer just an demjenigen Tag die gesuchten Informationen nicht erhielten als ohnehin nur 21 an der Umfrage teilnahmen.
Konfidenzintervall der Zielerreichungsquote
Wir können die Ergebnisse jeden Tages betrachten als eine Stichprobe aus der Population. Die der Zielerreichung zugrunde liegenden Daten sind binäre Daten; bis auf sehr wenige Ausnahmen (siehe oben) ist n > 30. Wir können entsprechend die Konfidenzgrenzen mittels des Wald-Verfahrens berechnen und damit den Bereich definieren, in dem die Zielerreichungsquote der Population mit einer definierten Wahrscheinlichkeit (hier mit 95%) liegt (im Chart durch die hellblauen whisker visualisiert).
Ein genauerer Blick auf die Breite der tagesbasierten Konfidenzintervalle zeigt den Einfluss von n: je größer n ist, desto schmaler ist das Konfidenzintervall. Das verweist auf die grundlegende Konstruktion des Konfidenzintervalls: Je größer unsere Stichprobe, desto näher liegt der aus der Stichprobe errechnete Parameter an dem wahren – uns aber unbekannten – Wert der Population.
Auf der Grundlage der tagesbasierten Werte beträgt der Mittelwert der Konfidenzintervalle 2 × 6,63 = 13,26 (Konfidenzniveau 95%). Dies ist die Intervallbreite um die mittlere Zielerreichungsquote von 76,9%.
Berechnen wir hingegen das Konfidenzintervall auf der Grundlage des gesamten Stichprobenumfangs von n = 98.197, so erhalten wir einen um mehr als eine Größenordnung präziseren Wert für das 95%-Niveau nämlich 2 × 0,26 = 0,52. Damit können wir reporten, dass im beobachteten Zeitraum die Zielerreichungsquote in der Population bei durchschnittlich 76,9% ±0,26% lag; diese Aussage können wir mit 95%iger Sicherheit treffen.
Wir können sogar das Konfidenzniveau auf 99,9% anheben; das Intervall erweitert sich – als Folge des gestiegenen kritischen Faktors von 3,2 – auf ±0,43%. Gemessen an typischen Untersuchungsgegenständen der User Experience erlaubt dies folgende ungewöhnlich präzise Aussage über den Populationswert: mit 99,9%iger Sicherheit lag die Zielerreichungsquote bei den Nutzern der Umkreissuche bei durchschnittlich 76,9% ±0,43%.
Konfidenzintervalle ersetzen keinen breiten Stichprobenumfang
Ich habe die Gelegenheit einer langfristigen Stichprobe genutzt und anhand der empirischen Daten geprüft, wie sich das KI auf Tagesbasis zu demjenigen über 600 Tage verhält. Beim Konfidenzintervall schlussfolgert man von Ergebnissen der Stichprobe auf die Population. Ich nehme mal die Daten von 600 Tagen stellvertretend für die Population und die Daten eines jeden Tages als Stichprobe. Die obere und untere Grenze des Konfidenzintervalls der jeweiligen Zielerreichungsquote sagt auf der Grundlage einer definierten Wahrscheinlichkeit voraus, ob sich der Populationswert innerhalb oder ausserhalb dieses Intervalls befindet.
Die Analyse der empirischen Daten ergibt folgene Werte für die Niveaus von 95% und 99,9%:
| MW_langfrist ausserhalb KI | Vorhergesagter Anteil gemäß Niveau | |
| 95% Niveau | 70 | 30 |
| 99,9% Niveau | 16 | 6 |
Tabelle 2: Vorhergesagte und tatsächliche Zahl der Mittelwerte, die ausserhalb des tagesbasierten Konfidenzintervalls lagen.
Die Anzahl der empirischen festgestellten Abweichungen liegen um mehr als Faktor 2 über derjenigen, die gemäß den Konfidenzniveaus zu erwarten wären. Darüber hinaus ist zu schlussfolgern, dass eine Verallgemeinerung der Zielerreichungsquote auf der Basis eines einzigen Tages nicht mehr valide Ergebnisse liefern kann; insbesondere, wenn man einen Tag erwischt, der nicht repräsentativ ist – siehe oben! Die Variablen „Wochentag“ oder „Tag im Jahresablauf unter Einfluss eines wichtigen Feiertages“ können ja erst im Versuchsaufbau berücksichtigt werden, wenn ihr Einfluss auf Nutzerverhalten und -erwartungen identifiziert wurde.
Also: Konfidenzintervall ist gut und schafft präzisere Aussagen. Trotzdem sollte man auf Umfang und Repräsentativität der Stichprobe achten. Sonst liegt man trotz Konfidenzintervallen in der Schätzung der Populationswerte daneben!
Epilog
Ich habe im Artikel erläutert, wie Konfidenzintervalle beitragen können, die Schlussfolgerungen von den aus Usabilitytests und Logfiles gewonnenen Werten auf die Population genauer zu beschreiben.
Dies gilt sowohl für die Betrachtung des User Researchers auf die eigene Arbeit am Untersuchungsgegenstand als auch für das Reporting gegenüber Auftraggeber, Produktowners oder Management. Die eigenen Ergebnisse werden weniger angreifbar, wenn die statistischen Kennwerte mit entsprechenden Konfidenzintervallen berichtet werden. Sauro und Lewis empfehlen dies. Dagegen habe ich von einem deutschen Experten gehört, dass er Konfidenzintervalle ermittelt, aber nicht reportet, da in der Präsentation die Zeit fehlt, um das notwendige statistische Verständnis beim Productowner / Management zu schaffen. Es würde mich freuen, wenn hierzu andere UX Researcher Erfahrungen beitragen könnten.
4 Literatur (online & offline)
Molich, R. et al, Comparative Usability Measurement in: Journal of Usability Studies, Vol. 6, Issue 1, November 2010, letzter Zugriff Sept 2014 http://www.dialogdesign.dk/tekster/cue8/CUE-8_JUS.pdf
Sauro, J. & Lewis, J: Quantifying the User Experience, Morgan Kaufmann, 2012
Rummel, Bernard: Tutorial Bummler und Schummler auf der MuC 2014. Wesentliche Inhalte des Tutorials sind publiziert in: Probability Plotting: A Tool for Analyzing Task Completion Times in: Journal of Usability Studies, Vol. 9, Issue 4, August 2014, letzter Zugriff Oktober 2014
Literatur-Hinweis zur Bestimmung des Punktschätzers bei kleinen Stichprobenumfängen:
Lewis, J.R. & Sauro, J. (2006) When 100% Really Isn’t 100%: Improving the Accuracy of Small-Sample Estimates of Completion Rates in Journal of Usability Studies Issue 3, Vol. 1, May 2006, pp. 136-150
Websites mit Berechnung von Konfidenzintervallen von Jeff Sauro
Berechnung von Konfidenzintervallen direkt aus Daten
Berechnung von Konfidenzintervallen zur Zielerreichung Erhellend sind die auf der Webseite dargelegten Erläuterungen, unter welchen Umständen welcher Algorithmus geeigneter ist.
Abstract
Zunehmend werden an die in der Business Intelligence erstellten Reports layouterische Anforderungen gestellt, die der optimalen Darstellung von Informationen, dem Corporate Design und der Überschaubarkeit dienen. Styleguides verwenden oftmals die für das Screendesign typische Einheit Pixel; Spreadsheet-Programme wie Excel, aus denen heraus die Reports erzeugt werden, verwenden dagegen metrische Einheiten, Punkt-Angaben oder sogar Einheiten, die in der visuellen Gestaltung unbekannt sind. Die Umrechnung der verschiedenen Einheiten ist von verschiedenen Faktoren abhängig und nicht immer trivial.
In diesem Artikel wird das quantitative Verhältnis der grafischen Einheiten <px>, <pt> und <cm> anhand von anschaulichen Beispielen aus der Sicht des Screendesigners erklärt. Umrechnungsformeln werden abgeleitet sowie der Einfluss des jeweiligen Betriebssystem veranschaulicht. Dabei fokussiert sich der Artikel auf Excel unter den beiden Betriebssystemen Windows und MacOS.
Layouterische Einheiten im Business Reporting
Ich werde immer wieder von Kollegen und Studenten gefragt, was der quantitative Zusammenhang zwischen Pixel und Point sei und ob es dafür eine einfache Formel gebe. Am liebsten wäre den Fragenden ein URL, in den man einen bekannten Wert eingibt und den gesuchten erhält.
Nun, solche URLs gibt es. Viele davon geben – unter gewissen Bedingungen – das gesuchte Maß richtig aus, manche geben es falsch aus. Wie so oft im Leben, kommt es auf die Bedingungen an, unter denen eine Frage gestellt wird und was genau man mit der Frage erfahren will. Context matters!
Insbesondere das in der Business Intelligence häufig verwendete Excel macht es dem Reportdesigner überaus schwer, da es in der von den meisten Usern verwendeten Normalansicht nicht nur ein eigenes, nicht weiter erkennbares Maßsystem für Längen verwendet, sondern davon sogar zwei verschiedene Systeme – je nachdem, ob es um die Höhe einer Zelle (=Zeilenhöhe) oder die Breite einer Zelle (= Spaltenbreite) geht. Ich werde in diesem Artikel die maßgeblichen Faktoren benennen und diese in eine Formel zusammenfassen.
Metrische Abmessungen und ihre Darstellung auf verschiedenen Screens
Ich werde im ersten Schritt phänomenologisch vorgehen und Untersuchungen in Excel in der (derzeit weit verbreiteten) Version 2010 vornehmen. Mittels verschiedener Monitore, Drucker und der beiden Betriebssysteme Windows 7 und MacOS werden die Faktoren, die die Darstellungsgröße beeinflussen, deutlich und quantifizierbar werden. Als Vorbedingung – also einer der Faktoren, von denen oben die Rede war – soll Excel die Tabellenblätter in der Größe 100% darstellen . Dies ist ja auch die Standardeinstellung und wird auch – so meine Alltagsbeobachtung – von Report Designern üblicherweise genutzt.
In einem Tabellenblatt in Excel auf meinem ThinkPad definiere ich eine Spalte mit der Breite von 10,0 cm. Lege ich auf dem Display des ThinkPads an diese Zelle einen Zollstock, so messe ich 7,4 cm Breite. Bewege ich dasselbe Tabellenblatt auf meinen externen Monitor, so messe ich 10,2 cm Breite. Wie ist dieser Unterschied zu erklären?

Abb 1 (Screenshot) : Eine Zelle mit 100 mm Spaltenbreite ….

Abb 2 (Foto) : … wird 7,5 cm breit dargestellt auf meinem Windows-Notebook ….

Abb 3 (Foto): … und mit 10,2 cm Breite auf dem Desktop-Monitor (geringe Abweichung in den Fotos ist verursacht durch Objektivoptik). Aber …
Das Pixel und die Pixeldichte eines Screens
Die Erklärung führt über den Begriff des Pixels – und zwar in seiner physikalischen Bedeutung. Die Einheit Pixel, abgekürzt „px“, ist entstanden aus dem Begriff „picture element“. Zuerst einmal meint dies also das kleinste Element eines gerasterten Bildes auf einem Screen. (Siehe hierzu den wikipedia-Artikel zu „Pixel„). In Falle der beiden o.g. Monitore wird das Bild auf einem LCD-Display mit seiner nativen Auflösung dargestellt – also ein technisches Setting, das heutzutage gängig an vielen Arbeitsplätzen ist. Die technischen Angaben beider Geräte bzw. die Informationen der Bildschirmauflösung und ein Nachmessen der physikalischen Breite des dargestellten Bildes ergeben die Werte 33,2 bzw. 51,9 cm.
Bei der Bestimmung der Pixeldichte stoßen wir zum ersten Mal auf die anglo-amerikanische Längeneinheit „inch“ (dt. Zoll). Umrechnung: 1 inch = 2,54 cm. Die Einheit der Pixeldichte ist [ppi] Pixel per Inch und meint evidenterweise die Anzahl der Pixel auf der Strecke eines Inches. Im folgenden wird die Pixeldichte errechnet, indem die bekannte Pixelbreite dividiert wird durch die gemessene Screenbreite [cm] , multipliziert mit dem Umrechnungsfaktor 2,54 [in/cm].

Formel 1: Bestimmung der Pixeldichte eines Screens
|
Ausgabegerät |
Auflösung |
Gemessene Screenbreite |
Pixeldichte (ppi) |
10 cm werden dargestellt als … (Messwerte) |
errechnete Werte |
|
ThinkPad eingebautes Display 15“ |
1680*1050 |
33,2 cm |
128,53 |
7,5 cm |
|
|
Eizo 24“ |
1920*1200 |
51,9 cm |
93,96 |
10,2 cm |
Wenn wir die obige Formel anders herum betrachten, so lässt sich mit ihr auch die Größe eines physikalischen Display-Pixels ausdrücken. Wenn die Pixeldichte des Eizo-Displays 94 ppi ist, so ist die Breite eines Pixels gleich dem Quotienten aus 1 inch = 2,54 cm und 94. Rechnerisch ergibt dies 0,027 und ein Blick in die technischen Spezifikationen des Monitors hat mir diesen Wert auch bestätigt.
Die verschieden großen Darstellungen meiner 10 cm breiten Spalte hängt also anscheinend mit den verschiedenen Pixeldichten der Displays zusammen. Aber keines der beiden Displays scheint die Spaltebreite korrekt abzubilden. Warum das so ist – dazu gleich mehr.
Bevor wir an diesen unterschiedlichen und vom definierten Ergebnis abweichenden Darstellungen verzweifeln, drucken wir unsere 10 cm breite Zelle aus und messen die Breite. Unter der Bedingung, dass wir den Ausdruck nicht skaliert haben, messen wir mit dem Zollstock 10 cm. Zum ersten Mal erhalten wir diejenige Länge, die wir definiert hatten! Endlich!

Abb 4 (Foto): … ausgedruckt hat die Spalte genau die definierte Breite von 10,0 cm (geringe Abweichung im Foto ist verursacht durch Objektivoptik)
Offenbar ist Excel gut darin, Längenabmessungen präzise an einen Drucker weiter zu geben, aber nicht so gut darin, Längenabmessungen an ein Display weiter zu geben. Ich führe dies darauf zurück, dass diese Software sehr print-nah entwickelt wurden und dass die Anschlussverwendung des Druckens einen hohen Stellenwert im Entwicklungsprozess der Software hat.
Das Betriebssystem und die normierte Pixeldichte
Die Erklärung der mehrfachen Abweichung auf den verschiedenen Displays führt uns zu einer weiteren Bedeutung der Pixeldichte. Es handelt hierbei darum, dass das Betriebssystem (in meinem vorliegenden Fall: Windows 7) von einem einheitlichen Wert für das Rendering auf dem Screen ausgeht: die angenommene Pixeldichte beträgt 96 ppi.
Dieser normierte Wert wird von Excel angesetzt, um eine in einer Längeneinheit definierte Strecke in Pixeln zu übersetzen. Mit diesem Wissen können wir nunmehr selbst die Anzahl der benötigten Pixel – nicht vergessen: unter Windows! – nach folgender trivialen Formel berechnen:
Formel 2: Pixelanzahl einer definierten Länge
Wenn wir die im untersuchten Fall gegebenen Werte einsetzen, so erhalten wir das Resultat, dass wir zu Darstellung von 10cm spaltenbreite 378 Pixel benötigen. Dasselbe sagt uns auch Excel direkt, wenn wir in die Darstellungsform „Seitenlayout“ wechseln und die Spaltenbreite verändern wollen. In einem Tooltip wird die jeweilige Breite n in der Einheit mm und in der Einheit px dargestellt.

Abb. 5 (Screenshot): In der Seitenlayout-Ansicht zeigt Excel die Breite in metrischer Einheit sowie in Pixel an.
<Warnender Einschub>Verwendet man dasselbe Arbeitsblatt und lässt es in der <Normalansicht> darstellen, so verändern sich die Pixelwerte: die Spalte hat nur 6,9 cm Breite, druckt aber immer noch mit genau 10,0 cm. Ich muß zugeben, daß ich noch nicht hinter die Ursache dieses Verhaltens gekommen bin. Hier besteht noch Untersuchungsbedarf. </Warnender Einschub>
Auf der Grundlage des dargelegten Zusammenhanges können wir nunmehr auch die obige Tabelle um die errechnete Angabe ergänzen, wie groß unsere 10 cm breite Spalte auf den Monitoren dargestellt wird. Dazu müssen wir einen Faktor bilden, der sich zusammensetzt aus der Pixeldichte des Windows-Sollwerts und der physikalischen Pixeldichte des jeweiligen Monitors. Die Resultate in der hinzugefügten rechten Spalte bestätigen unsere Meßergebnisse.
|
Ausgabegerät |
Auflösung |
Gemessene Screenbreite |
Pixeldichte (ppi) |
10 cm werden dargestellt als … (Messwerte) |
errechnete Werte |
|
ThinkPad eingebautes Display 15“ |
1680*1050 |
33,2 cm |
128,53 |
7,5 cm |
7,47 cm |
|
Eizo 24“ |
1920*1200 |
51,9 cm |
93,96 |
10,2 cm |
10,22 cm |
Ich öffne nunmehr dasselbe Tabellenblatt der Excel-Datei mittels Excel 2010, das auf meinem Mac installiert ist. Da mein Mac ebenfalls über ein Display derselben Auflösung und derselben physikalischen Screengröße verfügt wie mein ThinkPad, erwarte ich bei der Definition einer 10 cm breiten Spalte ebenfalls eine Darstellung von 7,5 cm. Aber weit gefehlt – die Messung ergibt eine Breite von 5,6 cm! Wieso das denn??!

Abb. 6: (Foto) Spaltenbreite von 10,0 cm wird auf dem MacBook mit 5,6 cm dargestellt.
(geringe Abweichung im Foto ist verursacht durch Objektivoptik)
|
Ausgabegerät |
Auflösung |
Gemessene Screenbreite |
Pixeldichte (ppi) |
10 cm werden dargestellt als … (Messwerte) |
errechnete Werte |
|
ThinkPad eingebautes Display 15“ |
1680*1050 |
33,2 cm |
128,53 |
7,5 cm |
7,47 cm |
|
Eizo 24“ |
1920*1200 |
51,9 cm |
93,96 |
10,2 cm |
10,22 cm |
|
MacBookPro 15“ |
1680*1050 |
33,2 cm |
128,53 |
5,6 (!) cm |
Dieses überraschende Ergebnis liegt darin begründet, dass das MacOS einen anderen Norm-Pixelwert verwendet. Auf dem Mac beträgt die Norm-Pixeldichte 72 pixel pro inch. Und dieser Wert ist nicht zufällig! Vielmehr misst der typografische DTP-Punkt („pt“) genau 1/72 tel eines Inches. (Quelle: http://de.wikipedia.org/wiki/Schriftgrad) Anders herum betrachtet: 72 DTP-Punkte ergeben genau ein Inch. Dass dies der Norm-Pixelwert des MacOS ist, hat historische Gründe: Der Mac Classic, der Mitte der 80er Jahre herauskam, sollte das Arbeiten im WYSIWIG-Modus ermöglichen und war auf die Verbindung von Print und Screen hin angelegt. Deswegen war ja auch die PostScript-Fähigkeit im Betriebssystem integriert und damit die Skalierbarkeit der entsprechenden Postscript-Schriften. Der im Gehäuse integrierte Monitor hatte eine Auflösung von 72dpi. Ein Objekt in der Größe eines Inches wurde damals also auf dem Monitor auch in der realen Größe angezeigt.
Wie gesagt: WURDE! Auf meinem MacBook Pro wird aufgrund des Norm-Pixelwerts von 72 ppi dieselbe Spaltenbreite schmäler dargestellt als auf dem Windows-Rechner. Das muss man erstmal sacken lassen, denn es klingt widersprüchlich: Die Pixeldichte wird im MacOS geringer angenommen und daher wird eine gegebene Breite schmäler dargestellt.
Um eine allgemeingültige Formel für die Abmessungen eines Objektes auf dem Screen aus den eingegebenen Längeneingaben zu erhalten muss ich die bei den Betriebssystemen unterschiedlichen Pixeldichten mit einfließen lassen:

Formel 3: Länge eines Objektes auf dem Screen in cm
Nehme ich die obigen Werte L(def) = 10 cm, ppi(screen) = 128,5 und setze ppi(OS) mit 72 für das MacOS, so erhalte ich tatsächlich den gemessenen Wert 5,6 cm als errechnetes Resultat.
Ebenso muss die Formel zur Berechnung der notwendigen Pixel um den OS-Faktor verallgemeinert werden:
Pixelanzahl = (Länge [cm] * Pixeldichtenormwert des OS) / 2,54.
Statt 378 px wie Windows erstellt das MacOS nur 284 px um 10cm darzustellen. Auf demselben Monitor wird also eine geringere Länge für dieselbe Anzahl Pixel angezeigt als unter Windows.
Mac-Point ungleich Win-Point
Als nächstes betrachten wir die typografische Einheit „Punkt“ (engl. „Point“). Wir werden feststellen, dass diese Einheit grundsätzlich den gleichen Regeln folgt wie auch die metrischen Einheiten – sowohl in Bezug zum Ausgabemedium Screen und Print wie auch in Bezug zu den beiden Plattformen Win 7 und MacOS.
Wir haben bereits gesehen, dass unter MacOS gilt: 72 px = 1 inch. Daher gilt innerhalb MacOS auch: 1 pt = 1 px = 0,353 mm. Unter Windows gilt aber: 1 px = 0,27 mm = 3/4 pt. Anders herum betrachtet: 1 pt = 4/3 px
Um es nochmals deutlich zu sagen: Die Einheit „px“ meint in diesem Zusammenhang nicht die physikalische Ausdehnung auf einem Screen, sondern die betriebssystemseitige Berechnungsgrundlage von Längenmaßen. Die je nach OS unterschiedliche Bestimmung von Größen führt in der Folge dazu, dass die von Excel in der Einheit <Point> definierten Schriftgrößen absolut verschieden groß sind.
Das folgende Screenshot-Composing zeigt die Screenshots einer Excel-Datei unter MacOS und unter Win 7. Der Vergleich der beiden Screenshots veranschaulicht, dass Excel Mac und Excel Win eine Schrift mit derselben Punktanzahl nicht gleich groß darstellen. Vielmehr entspricht 18 pt Schriftgröße unter Windows dem 1.25 fachen der Schriftgröße unter Mac, also einer 24 pt Schriftgröße. Auf der Grundlage des weiter oben Dargelegten ist das auch folgerichtig, da ein Win-Point = 4/3 px und ein Mac-Point = 1 px.

Abb. 7 (Composing Screenshot) Bei identischer Screenauflösung wird dieselbe Textgröße unter MacOS und Win7 unterschiedlich groß auf dem Screen dargestellt.
Werden beide Texte ausgedruckt, so ist alles gut: Schrifthöhen und Schriftlängen von Excel Mac und Excel Win sind identisch. Wenn also bedrucktes Papier das Zielmedium ist, so spielt die Plattform keine Rolle. Wird aber für den Screen produziert, so erhält man unterschiedliche absolute Größen derselben Punktdefinition.
Umrechnung Point und Pixel in Abhängigkeit des Betriebssystems
Es gilt also folgende grundlegende Beziehung zwischen Point und Pixel unter Berücksichtigung des jeweiligen OS:
Mac: 1 px = 1 pt. So einfach kann die Welt sein!
Win: 1 pt = 4/3 px und 1 px = 3/4 pt. Windows war halt schon immer etwas schwieriger!
Formel 4: Konvertierung von Pixel nach Point und umgekehrt unter WIndows und MacOS.
Ein Anwendungsbeispiel
Das folgende kleine Beispiel soll innerhalb des eingangs skizzierten Nutzungskontextes die Anwendung der Konvertierungsformeln erklären.
Die Vorgaben: Ein Styleguide schreibe eine Schriftgröße von 24px für die Überschrift des Reports vor. Der Abstand zu einer unteren Linie solle 16px betragen.
Die Umsetzung in Excel Win: Als Schriftgröße wird entsprechend der Umrechnungsformel 18 pt definiert. Die Höhe der Headline-Zelle wird 22 pt, damit Akzenthöhe und Unterlängen nicht abgeschnitten werden; die vertikale Ausrichtung ist zentriert. Die zusätzliche Reihe produziert den notwendigen Abstand zur Linie, die als Rahmenlinie an der Unterseite der Zelle definiert wird. Die Höhe der Zeile beträgt entsprechend der Konvertierungsformel 12 pt (=16 px). Wir erhalten das im Screenshot dargestellte Ergebnis, das nahezu exakt den Vorgaben entspricht.

Abb 8 (Composing vergrößerter Screenshot): Eingabe von Schriftgröße und Zeilenhöhe als Punktgrößen in Excel-Win und Messung des Resultats in px.
<Hinweis> Die Einheit der Zeilenhöhe wird in der Excel-Normalansicht in Punkt gemessen, aber nicht angezeigt. Klickt man zwischen zwei Zeilen, so wird zusätzlich zur Punkthöhe der Zeile auch die (korrekt) umgerechnete Höhe in px angezeigt. </Hinweis>
<Vorsicht> die Breite von Spalten wird in der Normalansicht NICHT in der Einheit <Punkt> definiert oder angezeigt, sondern in der Einheit Zeichenanzahl. Siehe auch diese Information der Online-Hilfe zu Excel 2010. </Vorsicht>
Ich denke, damit habe ich die Zusammenhänge zwischen den metrischen Einheiten, Pixeln und Points für’s erste erschöpfend erklärt. Ich mache daher hier einen Punkt, … nunja … Point!
Prolog
Die Leap Motion ist ein kleines Gerät für den Desktopgebrauch, das Hand- und Fingerstellungen extrem genau erfasst. Im Frühsommer 2012 wurde dieser Controller angekündigt; man konnte ihn nur vorbestellen, er wurde noch nicht ausgeliefert. Und ich bestellte ihn auch sofort. Was mich daran interessierte, waren die Möglichkeiten eines Interfaces, das ohne Stift, ohne Tastatur, ohne Maus funktioniert; nur mittels der eigenen Finger und Hände wird gesteuert, navigiert, geschaffen. Ein Eingabegerät, das den Raum vor einem Screen abtastet: dreidimensional und berührungslos.
Vielleicht – so schien es mir zum damaligen Zeitpunkt – ist es möglich, mit dem Controller und entsprechender Software sogar ein wenig in Richtung des Films Minority Report zu kommen. Genauer: in Richtung des Systems g-speak von John Underkoffler, der die Gesten für Minority Report entwickelte, wie er in einem TED-Talk erzählt. Minority Report für den Desktop!!! Euphorie und Spannung auf das mit diesem Controller Kommende machten sich in mir breit!

Herumrühren im 3-D Raum. Spielerische Auseinandersetzung mit der Leap Motion und dem dazu gelieferten Visualizer
Nun, die Auslieferung der Leap Motion erfolgte im Frühsommer 2013, also ein Jahr später, und die ersten Versuche mit vorhandenen Apps aus dem Leap Motion AppStore ließen mich alles andere als Tom Cruise fühlen: Es gab gerade eine Handvoll sinnvoller Anwendungen, kaum eine lief problemlos und auch wenn sie lief, war der joy of use … nunja … überschaubar. Auch die ersten systematischen Untersuchungen zur User Experience und zum Einsatzbereich durch UID brachten Ernüchterung. Mein erstes Resumee im Sommer 2013: Nein, dies war (noch?) kein technologischer Durchbruch wie einst das iPhone oder das App-Konzept, kein Quantensprung im Interface-Design. Und es war meilenweit von der Eleganz und Wirksamkeit eines g-speak entfernt.
Nutzungsszenario Selektieren im Farbwürfel
Nun, nachdem meine Illusionen und Hoffnungen von der technischen Realität zerblasen wurden, wollte ich schauen, was mit den vorhandenen Mitteln Sinnvolles und Einfaches bewerkstelligt werden kann. Ausloten, was geht und wie es sich anfühlt war der nächste Schritt. Ein sinnvolles und kleines Aufgabenszenario musste her. Die Aufgabe, im dreidimensionalen Raum zu navigieren und einen Raumpunkt zu selektieren erschien mir hinreichend beschränkt und einfach. Im Kontext einer Selektion einer Farbe ergibt dies ein durchaus sinnvolles Nutzungsszenario für beispielsweise einen Arbeitsschritt eines Screendesigners. Bewusst sollte diese Aufgabe isoliert betrachtet werden; die Frage nach der Einbettung dieses Vorgangs in einen größeren Nutzungszusammenhang wurde ausgeklammert.
Als Screendesigner kennt man das Modell des RGB-Farbraumes, in dem jeder Farbpunkt durch ein Tripel der Werte aus den 3 Farbachsen Rot, Grün und Blau dargestellt wird. Das zugrunde liegende räumliche Modell stellt einen Würfel dar, in dem jede der drei Achsen positive ganzzahlige Werte zwischen 0 und 2^8-1 = 255 annehmen kann. Das Tripel (0,0,0) ergibt schwarz und ist die dunkelste Farbe, die in diesem Farbraum dargestellt werden kann; das Tripel (255,255,255) ergibt die hellste Farbe Weiss. Die RGB-Farben werden durch additive Farbmischung erzielt; daher werden die Farben grundsätzlich umso heller, je höher die Werte sind. Insgesamt sind in diesem Farbraum (2^8)^3 = ca. 16,7 Mio Farben darstellbar.

RGB-Würfel: Betrachter schaut auf die ihm zugewandten Aussenflächen. Der weisseste Punkt ist die dem Betrachter am nächsten liegende Ecke des Würfels oben und vorne (R= 255, G=255, B=255)

RGB-Würfel: Betrachter schaut durch den Würfel auf die ihm abgewandten Aussenflächen. Der schwärzeste Punkt ist die vom Betrachter am weitesten entfernte Ecke des Würfels, am Schnittpunkt der drei Farbachsen und damit am Ursprung des Koordinatensystems (R=0, G=0, B=0)
Ein studentisches Projekt mit Schwerpunkt Interaction Design
Eine Projektgruppe des Studiengangs ON an der DHBW Mosbach setzte im im Wintersemester sich mit der Aufgabe auseinander, ein funktionstüchtiges Design des Interfaces zur Navigation innerhalb des RGB-Würfels unter Verwendung der Leap Motion zu konzipieren. Die Konzeption umfasste die Gestaltung der Interaktionen, die Gestaltung des visuellen Feedbacks auf dem Screen und die codemäßige Umsetzung in einem Funktionsprototypen. Selbstverständlich wurde iterativ vorgegangen, da von vornherein klar war, dass Coding, Interaktionen und visuelles Feedback in hohem Maße voneinander abhängig sind.
Die erzielten Resultate und identifizierten Knackpunkte beim Design des Interfaces und der Interaktionen sollen in diesem Artikel betrachtet werden; zusätzlich werde ich Überlegungen zur Verbesserung der Benutzbarkeit dieses Interfaces anstellen. Das Interface läuft im Webbrowser; die Projektgruppe hat das Interface live gestellt.
Prinzip der Verankerung
Zum Markieren einer einzelnen Farbe des RGB-Würfels muss eine bestimmte natürliche Geste gebildet werden. Die Geste des ausgestreckten Zeigefingers des Nutzers zusätzlich mit horizontal abgewinkelten Daumen, von den Studenten sinnigerweise „Gangster-Pistole“ genannt, zielt auf einen Punkt des vor dem Nutzer liegenden Raumes. Die Markierung im Würfel verbindet sich mit dem Zeigefinger und folgt dessen Bewegungen. In solchen Fällen spricht das Interaktionsdesign von dem Prinzip der Verankerung, auf das die direkte Objektmanipulation aufbaut. (Dorau, S. 106).

Navigation im Farbwürfel mittels Markierungs-Geste aus Sicht des Nutzers. Im Browserfenster erscheint das komplette visuelle Interface mit Farbwürfe, der markierten Farbe und der zuletzt gespeicherten Farbe.
Die Spitze des Zeigefingers deutet auf eine Raumzelle (gewissermaßen ein „Voxel“ = Volumen Element) des Würfels. Indem der Zeigefinger sich durch die Hit Area über dem Leap Controller bewegt, verändert sich die Position des markierten Punktes innerhalb des Farbwürfels.
Die Markierung von Farbzellen funktioniert sowohl in der Annäherung von außen als auch durch Gestenänderung von innen. Aus der Perspektive des Nutzers kann ich die Markierungsgeste ausserhalb der Hit-Area formen und mich auf den Würfel zubewegen. Die ersten erkannten Punkte liegen in diesem Fall an derjenigen Würfelaussenseite, von der aus die Hand sich dem Controller annähert. Von dort aus bewege ich die Hand weiter nach innen in den Würfel und / oder nach oben / unten / links / rechts bis ich den gewünschten Punkt erreicht habe.
Umgekehrt kann ich auch mittels des Nicht-Markierungsmodus meine Hand in den Eingabebereich einführen, ohne eine erneute Markierung auszulösen. Erst wenn ich innerhalb des Eingabebereiches Zeigefinger und Daumen spreize, erkennt das System den Markierungsmodus und zeigt mir den nunmehr neu markierten Punkt innerhalb des Würfels an.
Beide Methoden funktionieren mit dem studentischen Prototypen – und das ist auch gut so, da es dem Nutzer Flexibilität gibt. Allerdings funktionieren sie derzeitig nicht zuverlässig und robust – dazu später mehr.
Wie soll nun die Interaktion gestaltet sein, wenn der Nutzer eine bestimmte Farbe im Farbraum erreicht hat und nun diese Farbe festsetzen oder speichern will oder gar die Hitarea mit der Hand verlassen will um, sagen wir mal, zwischendurch einen Schluck zu trinken ? Anders als mit der Maus, die man einfach loslässt und mit der Hand in die dritte Dimension geht, ist bei einem Scannen des dreidimensionalen Raumes nicht möglich, mit der Hand in eine andere Dimension zu wechseln.
An dieser Stelle bietet sich an, durch verschiedene Gesten verschiedene Modi zu repräsentieren und damit die existierende Verankerung zu verlassen. Durch Ändern der Geste verlasse ich den Markierungsmodus. Ich kann beispielsweise zu einer undefinierten Geste greifen, z.B. geballte Faust, und damit die Hitarea zu verlassen ohne die Markierung zu verändern. Oder ich will die markierte Farbe speichern und verlasse die Markierungsgeste, indem ich den Daumen „einklappe“, also nur den Zeigefinger ausstrecke (Selektionsmodus) und als nächste Bewegung die Tap-Geste ausführe (Zeigefinger „drückt“ deutlich in Richtung Screen)
Zwischenbemerkung:
Ich kann mit den vorhandenen Interaktionspatterns niemals eine bereits markierte Farbzelle nutzen, indem ich sie beispielsweise verschiebe; vielmehr fange ich die Markierung zwangsläufig immer wieder neu an. Daher sehe ich Potential für weitere Gesten angesichts eines Real-World- Nutzungsszenarios, bei dem Farben nicht nur neu definiert werden, sondern oftmals umdefiniert werden oder in iterativen Schritten ihre finale Bestimmung erhalten. Es wäre bei einer Weiterführung des Projektes über die Gestaltung und die Steuerung eines Bearbeiten-Modus nachzudenken, bei dem der User eine bereits markierte Farbe gezielt in ihren Werten verändern möchte.
Gesten als Metaphern der realen Welt
Die implementierten Gesten und ihre korrespondieren Funktionen basieren weitestmöglich auf Metaphern der realen Welt:
- „Gangster-Pistole“ > Zielen: Farbe markieren
- Zeigefinger allein > auf etwas Bestimmtes zeigen: Farbe selektieren
- Tap > mit Zeigefinger drücken: Farbe speichern
- Circle > horizontale, halbkreisförmige Bewegung: Würfelausrichtung ändern
Je mehr Entsprechung die Geste in der Realität hat, desto leichter erlernbar und besser merkbar ist sie. Tap-Geste und Circle-Geste sind aus dem Software-Development-Kit von LeapMotion entnommen.

Visuelle und textuelle Beschreibung der im Colorpicker verwendeten Gesten im Hilfelayer der Colorpicker Applikation.
Eigenlokation im Raum und ihr visuelles Feedback
Während der Interface-Entwicklung wurde schnell klar, dass eine reine Kennzeichnung des annavigierten Punktes nicht ausreicht: die Darstellung des Voxels erfolgt auf dem (2-dimensionalen) Screen. Eine Punktmarkierung innerhalb des (von einem fixen Betrachterstandpunkt aus) projizierten Würfels macht den Raumpunkt für den Nutzer nicht nachvollziehbar und ist auch nicht eindeutig, wie die folgende Skizze exemplarisch illustriert.

Beide Punkte P1 und P2 bezeichnen im RGB-Würfel verschiedene Farben, liegen aber aus der festen Betrachterperspektive auf derselben Sichtlinie. Erst die zusätzliche Darstellung von Loten ergänzt die zur eindeutigen Ortsbestimmung notwendigen Informationen.
Verbessert werden kann die unzureichende Eigenlokation, indem zusätzlich zum annavigierten Punkt die Lotrechte auf die 3 Aussenflächen des Kubus dargestellt werden. Weiterhin werden die numerischen RGB-Werte direkt neben dem markierten Punkt dargestellt, damit die exakte Raumposition auch direkt im Wahrnehmungsfokus des Users liegt und simultan erfasst werden kann.
Farbidentifikation als Grundlage für Steuerbarkeit
Bisher wurde die Navigation im Farbwürfel unter dem Aspekt des Ansteuerns eines Koordinatenpunktes im Würfel betrachtet. Dies ist aber kein Zweck an sich, sondern nur ein Mittel, damit der Nutzer innerhalb des Farbwürfels explorieren kann, jede einzelne markierte Farbe sowohl adäquat wahrnehmen und ggf. auch speichern kann. Es wurde der Projektgruppe sehr schnell klar, dass die punktuelle Markierung keine ausreichende Fläche aufweist, um dies zu leisten. Deswegen wurde diese Anzeigefläche ausserhalb des Würfels gelegt.

Großflächige Farbdarstellung ausserhalb des Farbwürfels.Oben die aktuelle markierte Farbe, unten die zuletzt gespeicherte.
Dies bietet verschiedene Vorteile gegenüber einer Platzierung innerhalb des Würfels:
- Die Farbflächenausdehnung kann so groß werden, dass die Farbe auch sicher vom Nutzer erkannt werden kann.
- Der Hintergrund kann homogen und stabil sein – im umgesetzten Prototypen ist der Hintergrund standardmäßig weiß. Innerhalb des Würfels ändert sich die Umgebung ständig durch die Navigation und kann zu verschiedenen Wahrnehmungsfehlern aufgrund von Simultankontrasten führen.
- Ein Vergleich der markierten Farbe mit einer vorher gespeicherten ist möglich. Im Prototypen funktioniert dies nachvollziehbar gut: das untere Farbfeld zeigt die zuletzt gespeicherte Farbe mit den RGB-Werten, die obere zeigt die aktuell markierte Farbe, die mit der Veränderung der Fingerposition aktualisiert wird. Dieser Refreshvorgang zeigt keinerlei spürbare Latenz.
Der Nachteil dieser Auslagerung ausserhalb des Würfels liegt darin, dass der Nutzer zum Erfassen und Vergleichen der Farbflächen seinen Wahrnehmungsfokus vom Würfel weg und hin zu den Farbfeldern bewegen muss. Für eine Optimierung des Interfaces wäre an dieser Stelle anzusetzen, designerische Alternativen zu entwickeln und eine die Leistungsfähigkeit der verschiedenen Designalternativen zu evaluieren.
Ob mit der sehr großzügigen Dimensionierung der Farbflächen im Prototypen etwas übers Ziel inausgeschossen wurde oder ob die gewählte Größe aufgrund des etwas größeren Betrachtungsabstanden angemessen ist, wäre in einer künftigen Weiterentwicklung zu evaluieren.
Darstellung der Farbumgebung
Für eine intuitive Navigation innerhalb des Farbwürfels reicht es nicht, dass der Nutzer den aktuell markierten Raumpunkt und die zugehörige Farbe erkennt. Darüber hinaus muss er in der Lage sein, die im Umfeld liegenden Farben zu erkennen, um bewusst in Richtung der gewünschten Farbeigenschaft zu steuern (z.B. heller oder dunkler, mehr in Richtung Rot oder mehr in Richtung Blau).
Im Rahmen der Entwicklung des vorliegenden Prototypen wurden zwei verschiedene Konzepte der Visualisierung angedacht:
- Darstellung der drei orthogonalen Schnittflächen zu einer markierten Farbzelle über den gesamten Würfel. Dabei stellt sich die Frage, wie mit den Bildteilen umgegangen werden soll, die durch vom Kamerastandpunkt aus verdeckt sind. Eine Variante wäre, die Aussenflächen schwarz zu halten, so dass nur die Schnittflächen dargestellt werden und Orientierung geben könnte.

Skizze der Visualisierung mittels dreier orthogonaler Schnittflächen, die durch die markierte Farbzelle gehen. Der RGB-Würfel hier wie der UI Prototyp so ausgerichtet, dass die vertikale Achse die Farbe blau kennzeichnet.
- Darstellung der drei orthogonalen Schnittflächen als Projektion auf die drei Aussenflächen. Dieses Konzept wurde im Prototypen umgesetzt. Wenn ich mit diesem Prototypen arbeitete, empfinde ich die ständigen Veränderungen der Aussenflächen als sehr störend und keineswegs als hilfreich um Farben bewusst anzusteuern. Mir fehlen unveränderliche Anhaltspunkte, aus denen ich ERSEHEN kann, welche Farbe in welcher Richtung liegt. Auch die Projektion auf die Aussenfläche in Zusammenarbeit mit den Loten der markierten Farbzelle suggeriert, dass die Farbzelle sich genau nicht auf den gezeigten Aussenflächen befindet; das Konzept ist also – zumindest für mich persönlich – kontra-intuitiv.
Im Rahmen einer Weiterentwicklung des Interfaces wird eine der Aufgaben sein, das erstgenannte Konzept zu implementieren und in einem Vergleich mit dem bereits implementierten Konzept zu evaluieren.
Message Bar
Sehr gut gelungen ist eine zu den direkten Zustandsänderungen zusätzliches Feedback des Systems an den Nutzer: <Farbe ist gespeichert> <Leap ist bereit> <Würfel wurde gedreht> (siehe Abbildung zur Farbdarstellung oben). Dem Nutzer gibt dies Sicherheit über die Ausführung von Befehlen oder auch über fehlerhaft ausgelöste Zustandsänderungen. Im Prototypen wird dieses Feedback textuell für einen kurzen Zeitraum in einer von oben in den Viewport fahrenden Message Bar gegeben. Absolut usable und gerade bei einem noch nicht ausgereiften Interface eine große Hilfe!
Schwachpunkte
Identifizierte und teilweise auch der Projektgruppe bekannte Schwächen des UI Prototypen liegen in verschiedenen Bereichen:
- Hängenbleiben („Freeze“) der Markierung beim visuellen Feedback
- „zittrige“ Eingabe
- unzuverlässige Erkennung von Gesten
Freeze
Grundsätzlich positiv ist die Latenzzeit beim Navigieren sehr gering d.h. als User habe ich den Eindruck, die Markierung folgt ausreichend schnell meinem Finger. Dies allerdings nur für einige Sekunden, danach kommt es allerdings häufig vor, dass die Markierung trotz weitergeführter Fingerbewegung für ein bis drei Sekunden stehen bleibt. Damit habe ich die Verankerung verloren, da mein Finger zwischenzeitlich eine neue Position eingenommen hat.Meinen gewonnenen Arbeitsfortschritt habe ich verloren und ich muss zwangsläufig mit der Navigation neu beginnen. Wenn ich es richtig verstanden habe, so sind diese Freezes das Ergebnis von zu großer Datenvolumina im Speicher.
Zittrige Eingabe
Ironischerweise ist die hohe Präzision des Leap Controllers auch ein Problem für die Steuerbarkeit. Innerhalb der Hit-area des Würfels ist es nahezu unmöglich, einen bestimmten Markierungspunkt trotz subjektiv stillgehaltenem Finger zu halten. Bereits unbeabsichtigte kleinste Bewegungen des Arms, der Hand oder des ausgestreckten Zeigefingers führen dazu, dass der gewählte Farbwert um ein bis zwei Werte in verschiedenen Achsen schwankt. Dieses ist insbesondere deswegen ein Problem, weil im Nutzungsprozess ein angesteuerter Farbwert im nächsten Schritt auch markiert bleiben und gespeichert werden soll. Dazu muss die Geste geändert werden und dies führt zu einer unbeabsichtigten Änderung der Fingerposition.
An dieser Stelle zeigt sich eine grundsätzliche Schwäche der Gestensteuerung gegenüber der Steuerung mit einem Eingabedevice wie einer Maus: der Nutzer kann die Maus liegen lassen und hat damit einen Ruhezustand hergestellt. Hat der Nutzer den Cursor einmal an eine gewüschte Stelle platziert, so muss er nichts weiter tun, um diese Stelle zu halten. Dagegen ist es bei der Fingergeste grundsätzlich anders: hier muss der Nutzer aktiv sich konzentrieren und unter Kraftaufbringung versuchen, die Geste an derselben Stelle schwebend zu halten.
Auch dieser ergonomische Nachteil bedarf der Optimierung des Interaktionsdesigns, um die präzise Steuerbarkeit zu gewährleisten. Mögliche Lösungsstrategien sind die Anwendung von Trägheitsalgorithmen oder das Zoomen in den Würfel hinein um das Verhältnis vonBewegung innerhalb der Hit-Area zu resultierenden Veränderungen im Farbwürfel zu verändern.
Unzuverlässige Erkennung von Gesten
Funktionen wie beipielsweise <Würfel drehen> oder <Farbe speichern> werden manchmal nicht ausgelöst werden, wenn ich es als Nutzer beabsichtige – oder andersherum genau dann ausgelöst werden, wenn ich es nicht beabsichtige, sondern eigentlich etwas anderes beabsichtige.
Epilog
Mir ist anhand der Analyse des Prototypen wieder einmal bewusst geworden, wie entscheidend das visuelle Feedback für die Steuerbarkeit eines Systems ist – gerade bei gestischer Steuerung. Und mir ist ebenfalls wieder einmnal bewusst geworden, wie ausgereift das WIMP-System ist – innerhalb seiner eigenen Grenzen und systemeigenen Beschränkungen. Ich werde daher auf die Unterschiede der beiden Interfaces (Leap Motion vs. klassische Maus) in einer der kommenden Blogartikel genauer eingehen.
Der Colorpicker mittels Leap Motion ist ein guter Start; aber für ein sauber und elegant bedienbares System ist noch einiges an Arbeit an Code und Interaktionen zu leisten. Neben der technischen Aushärtung des Systems sollte die weitere Entwicklungsarbeit auch Methoden und Vorgehensweise des User Centered Designs integrieren. Vielleicht interessieren sich im kommenden Winter Studenten am FB ON für die Weiterführung des Colorpicker UIs …
Basics
Quelle:
Konzept eines UIs zur Farbselektion aus einem RGB-Würfel mittels Leap Motions Controller
Jasmin Wagner, Domenik Niemietz, Michael Tebbe, Konstantin Scharow (Studiengang Online Medien an der DHBW Mosbach, 5. Semester) (http://www.dhbw-mosbach.de/studienangebote/onlinemedien.html) Februar 2014
Die Arbeit entstand im Rahmen der LV Multimediales Informationsdesign, Betreuung: Lothar B. Blum.
Technische Daten:
Verwendete Spoftware: LeapMotion Version 1.1.3
Der Prototyp läuft im Webbrowser. Am besten lief der Colorpicker unter Firefox. Meinen Analysen basieren auf FF 28.0
URL: http://leap.2fq.de/
Hinweise:
Ich habe festgestellt, dass die Leap Motion trotz der Infrarotsensoren einer gleichmäßige Umgebungsausleuchtung bedarf. Schlaglichter in der Form von einseitigem Tageslicht oder nahestehende Lampen mit Punktlicht können schnell zu Fehlerkennungen und fehlerhaftem Verhalten führen.
Grundlagenliteratur:
Ich möchte auf das ausgezeichnete Buch „Emotionales Interaktionsdesign – Gesten und Mimik interaktiver Systeme“ von Rainer Dorau hinweisen. Der Hauptitel ist ein wenig irreführend, denn emotional ist an diesem Buch nichts. Ganz im Gegenteil: es befasst sich sehr analytisch und rational mit den Interaktionsmöglichkeiten von computergesteuerten Systemen. Sein Schwerpunkt liegt auf den Touch-Systemen.
Dorau, Rainer: „Emotionales Interaktionsdesign – Gesten und Mimik interaktiver Systeme“, Heidelberg 2011 (Springer)
Während „Google Trends“ nur relativ grobe Abfragen zulässt, kann man mit „Google Insights for Search“ schon einiges mehr anfangen. Insbesondere erlaubt das System das Setzen zusätzlicher Filter für die Suchanfragen, und es hat obendrein ein genaueres und feineres zeitliches Auflösungsvermögen. Wer von Trends auf Insights umsteigt, muss sich allerdings an einen anderen Index gewöhnen (warum ist mir persönlich bis heute nicht klar). Doch keine Sorge, das Grundprinzip bleibt gleich. Auch hier geht es um die relative Verteilung von Suchanfragen über die Zeit und einen Vergleich der relativen Häufigkeiten von Suchanfragen bei mehreren Suchwörtern.
Bevor wir uns um die Analyse und Interpretation einiger Beipsiele kümmern, werfen wir zunächst einmal einen Blick auf das Interface von Google Insights for Search:

- Abbildung 1: Das Interface der „Google Insights for Search“ eine größere Ansicht erhalten Sie, wenn sie auf das Bild klicken.
Von links nach rechts finden wir…
- …unter „Vergleichen mit“ eine Auswahl, mit deren Hilfe man angeben kann, ob man die Häufigkeit von Suchbegriffen weltweit oder in einer definierten Region untersuchen möchte (d.h. genau einer, nicht mehreren). Wählt man hier anstelle von Suchbegriffen „Standorten“, lässt sich das Suchverhalten an zwei Standorten für einen Suchbegriff analysieren (d.h. wiederum genau einen, nicht mehrere).
- …unter „Suchbegriffe“ ein Eingabefeld für einen Suchbegriff, in dem sich die gängigen Operatoren der Google-Suche einsetzen lassen, also Anführungszeichen für die wörtliche String-Suche, „+Keyword“ für obligatorische zusätzliche Suchbegriffe, „-Keyword“ für eine Suche, die nur Treffer ohne das zusätzliche Keyword enthält usw. Mit einem Klick auf „+Suchbegriff hinzufügen“ kann man genau dies tun, und zwar genau 4 mal. Einfacher gesagt: es können maximal 5 Suchbegriffe miteinander verglichen werden.
- …unter „Filter“ ein eigentlich weitgehend selbsterklärendes Interface zur Spezifikation von Suchbereichen, die von den Benutzern bei der Suche aktiviert waren (Web, Bilder, News und Produkte) Zeitperioden und Kategorien des Google-Katalogs. Während im ersten Fall klar ist, dass z.B. nach dem Eingeben eines Suchwortes die Suche auf „Bilder“ oder „Produkte“ eingeschränkt wurde, ist letzteres für mich so nicht eindeutig. Da die genaue Herkunft und Zusammensetzung dieser Daten auch nach einigen Recherchen nicht verstanden habe, und die Angabe einer Kategorie obendrein nicht selten zu Null-Treffer-Resultaten führt, gehe ich auf diesen Aspekt im folgenden nicht näher ein.
Vergleich von Suchwörtern
Eine vergleichende Analyse mehrerer Suchwörter ist mit Google Insight for Search in einem Schritt möglich, wobei für einen einzelnen Vergleich der Zeitraum und die Region konstant gehalten werden. Die folgende Grafik zeigt z.B. den Prozess der Ablösung des Buzzwords „Web 2.0“ durch das Buzzword „Social Media“ im Verlauf der letzten 7 Jahre weltweit.

Abbildung 1: Verlauf des weltweiten Interesses für "web 2.0" vs. "social media" (zum Vergrößern bitte Grafik anklicken)
Was bedeuten die Zahlen?
Diese Frage stellt sich natürlich sofort, wenn man die Grafiken von Google Insight for Search sieht. Sie ähneln auf den ersten Blick dem Erscheinungsbild den Darstellungen von Google Trends zum Verwechseln, doch der Wertebereich ist anders aufgebaut. Der höchste Wert, den eine Kurve in Google Insight erreichen kann ist anscheinend 100…? So ist es. Der höchste in der abgefragten Zeitperiode gemessene Wert wird gleich 100 gesetzt, und alle anderen Werte werden dann an diesem relativiert. Da sich Google nicht die Mühe macht, den eigenen Indizes anständige Namen zu geben (eine sträfliche Unterlassung, wie ich finde), möchte ich den Search-Volume-Index von Google Insight for Search in Anlehnung an den vorigen Artikel einfach „SVI-2“-Wert nennen.
Die Formel für den SVI-2 Wert ähnelt nun der für den SVI-Wert (von Google Trends) auf den ersten Blick zum Verwechseln:

- Formel 1: Formel zur Bestimmung des SVI-2 Werts für ein gegebenes Keyword an einem bestimmten Stichtag. (Erläuterungen im Text)
Eine Variante des Beispiels aus dem ersten Artikel mit „diät“ als Suchwort und dem 01. Mai als Stichtag verdeutlicht, wie der Index funktioniert. War der höchste gemessene Wert in der zu betrachtenden Untersuchungsperiode 500 Suchanfragen, und ist der beobachtete Wert am 01. Mai = 250, resultiert ein SVI-2 Wert von 50:

Formel 2: Berechnungsbeispiel für den SVI-2 Wert
Der SVI-2 Wert gibt also in Prozent an, wie häufig das Suchwort an einem Tag gesucht wurde, jeweils bezogen auf den Tag mit den meisten Anfragen.
- SVI-2 = 10 bedeutet: An diesem Tag wurden 10% der am Tag mit maximalem Suchtraffic beobachteten Anfragen gezählt.
- SVI-2 = 70: Es wurden im Vergleich mit dem Tag mit maximalem Suchtraffic 70% Suchanfragen gezählt.
- usw.
Und damit ist natürlich auch zugleich klar, dass der SVI-2 Wert maximal einen Wert von 100 annehmen kann.
Die oberhalb der Grafik in Abbildung 1 unter „Gesamt“ eingeblendeten Werte geben an, welchen Mittelwert man für den SVI-2 Wert in der gegebenen Periode erhält. Wäre „Gesamt“ gleich 100, würden also an jedem Tag exakt gleich viele Suchanfragen gestellt, und die Kurve wäre gar keine Kurve, sondern eine Gerade. Anders gesagt: Je geringer der Wert für „Gesamt“ ausfällt, desto stärker schwanken die Werte während der untersuchten Periode – hierzu kommen noch Beispiele.
Anwendungsbeispiel: Vergleich zweier Markennamen
Stimmen die Umstände, ist so über Google Insight z.B. eine sehr einfache und ziemlich objektive Bestimmung der Popularität von Marken möglich. Dies zeigen die beiden folgenden Abbildungen, auf denen die relative Häufigkeit der Suchbegriffe „nike“ und „adidas“ in den USA und in Deutschland verglichen wurden:

Abbildung 2: Verlauf des SVI-2 Index für die Suchbegriffe „adidas“ und „nike“ von 2004 bis heute in den USA. (Die Grafik ist durch Anklicken vergrößerbar.)

Abbildung 3: Verlauf des SVI-2 Index für die Suchbegriffe „adidas“ und „nike“ von 2004 bis heute in Deutschland. (Die Grafik ist durch Anklicken vergrößerbar)
- Man erkennt sehr schön, dass sich das Interesse an den Marken Adidas und Nike in Deutschland etwa gleich verteilt, mit leichten Vorteilen für Adidas. Die Mittelwerte der SVI-2 Werte liegen relativ dicht zusammen, nämlich bei 62 für adidas und 53 für nike.
- In den USA liegen die Verhältnisse umgekehrt: hier hat Nike sehr eindeutig die Nase vorn im Wettbewerb um die Suchanfragen. Die Mittelwerte liegen bei 75 (Nike) und 19 (Adidas).
Besonders interessant ist die Zeitperiode Mitte 2006. Damals wurde von Adidas eine gigantische Marketing-Kampagne zur Fußball-WM gestartet – nachzulesen z.B. in einem zeitgenössischen Beitrag der Deutschen Welle. Die Auswirkungen der Kampagne können wir in der Grafik für Deutschland (Abb. 3) sehr gut sehen: Die blaue Kurve zeigt einen deutlichen Ausschlag nach oben. Tatsächlich liegt Mitte 2006 der höchste jemals gemessene Wert für „adidas“. „Nike“ hat ebenfalls ein lokales Maximum in seiner Popularität Mitte 2006, Adidas ist jedoch der klare Gewinner. In den USA zeigt sich das öffentliche Interesse für die Marken im gleichen Zeitraum dagegen ziemlich unbeeindruckt – sicherlich kann man dies als Symptom des chronisch geringen Interesses der US Bevölkerung an Fußball werten.
Ein Benchmarking der Markenpopularität ist also durchaus möglich, allerdings: Ob sich solche Beobachtungen dann auch in Umsatz oder Marktanteile übersetzen lassen, ist aufgrund des SVI-2 Index natürlich nicht sagen. Aber man erkennt an dem Beispiel sehr schön, dass sich eine Beobachtung von SVI-2 Werten für Firmen lohnen könnte – umso mehr, wenn man berücksichtigt, dass die Daten kostenlos sind.
Beobachtung von Zeitverläufen
Google Insight ist besonders auf die Beobachtung von Zeitverläufen ausgelegt. Dies kann man leicht nachweisen, wenn man Begriffe eingibt, bei denen mit saisonalen Veränderungen im Interesse zu rechnen ist, z.B. „Ostern“ und „Weihnachten“. Auch einmalig auftretende Ereignisse lassen sich sehr gut sichtbar machen. Bei der folgenden Grafik handelt sich um die Häufigkeit des Begriffs „beaujolais“, gekoppelt mit den Jahreszahlen von 2007 bis 2010.

Abbildung 4: Häufigkeit des Begriffs „beaujolais“ mit zusätzlicher Jahreszahl von 2007 - 2011 (Die Grafik ist durch Anklicken vergrößerbar)
Es scheint, das Interesse für Beaujolais nimmt tendenziell zu…
Zu beachten ist, dass der Gesamt-SVI-2-Wert bei diesem Beispiel in allen Fällen sehr klein ist. Dies ist auch plausibel: es gibt nur ganz wenige hohe und andererseits sehr viele Werte, die nahe bei Null liegen. Dies führt in der Konsequenz zu einem niedrigen Durchschnitt. Drei Faustregeln für die Interpretation des „Gesamt“-SVI-2 kann man festhalten:
- 1. Hohe Werte entstehen, wenn es nur geringe Schwankungen in den Werten gibt. Dann weichen die beobachteten Häufigkeiten an den einzelnen Tagen im Durchschnitt nur relativ wenig vom Maximum ab.
- 2. Niedrige Werte entstehen bei starken Schwankungen, vor allem dann, wenn es nur einzelne Maxima und ansonsten sehr niedrige Werte gibt. Wenige Ausreißer nach oben können dann ein niedriges durchschnittliches Interesse nicht stark beeinflussen.
- 3. Regel 1. und 2. gelten nur, wenn einzelne Keywords abgefragt werden. Gibt man mehrere Suchwörter gleichzeitig ein, können niedrige Werte für den Gesamt-SVI-2-Wert auch anders entstehen, nämlich einfach dadurch, dass einer der Begriffe sehr viel seltener gesucht wird. Diesen Fall hatten wir beim Vergleich von Nike und Adidas in den USA (s.o., Abbildung 2).
Gleichzeitige oder getrennte Betrachtung von Verläufen
Um die Funktion von Google Insight richtig anwenden und die Ergebnisse interpretieren zu können muss man wissen, dass es einen großen Unterschied macht, ob ein Wort alleine oder zusammen mit anderen eingegeben wird. Gibt man z.B. nacheinander drei unabhängige Abfragen für die Begriffe „Syrien“, Ägypten“ und „Tunesien“ ein und beschränkt die Suche auf Deutschland, erhält man die in der folgenden Abbdildung zusammengestellten Grafiken.

Abbildung 5: Interesse an den Ländern Syrien, Tunesien und Ägypten in Deutschland von November 2010 bis Juni 2011 in drei getrennten Abfragen (Die Abbildung ist durch Klicken vergrößerbar).
Man erkennt, dass es in Ägypten und Tunesien während der Höhepunkte der Demokratie-Bewegungen in diesen Ländern eindeutige Spitzen oder „Zacken“ im Interesse gibt, die danach wieder abflauen. In Syrien ist das Auf und Ab während der revolutionären Entwicklung dagegen deutlich gemäßigter. Dies manifestiert sich auch in den Durchschnittswerten für den SVI-2 Index, die (auf der Grafik nicht zu sehen). Sie liegen…
- …für Syrien bei 40,
- für Tunesien bei 27,
- für Ägypten bei 23.
Dies spricht dafür, dass Syrien mit seiner repressiven Informationspolitik relativ gut verhindern konnte, dass die Vorgänge im eigenen Land Gegenstand des Interesses der deutschen Öffentlichkeit werden.
Wichtig ist, dass bei dieser Betrachtung jedes Keyword seine eigene Referenz ist, d.h. wir können keine Aussagen darüber machen, ob es Häufigkeitsunterschiede zwischen den Begriffen gibt. Die ist aber möglich, wenn wir die Intensität und Verlauf des öffentlichen Interesses für alle drei Länder in einer gemeinsamen Abfrage vergleichen:

Abbildung 6: Verlauf des Interesses für Tunesien, Ägypten und Syrien bei vergleichender Abfrage in Google Insights for Search (Abbildung durch Klicken vergrößerbar).
Was können wir aus dem Ergebnis ableiten? Zunächst ist der Verlauf der Kurve und der durchschnittliche SVI-2-Wert für Ägypten identisch mit der Einzelabfrage in Abbildung 5. Ägypten liefert also den Bezugswert mit maximalem Traffic. Da Tunesien und Syrien nun ebenfalls an dem maximalen Such-Traffic für Ägypten relativiert werden, ist das Niveau der Linien für diese Länder plötzlich sehr viel niedriger als bei den Einzelabfragen. Das bedeutet inhaltlich, dass das Interesse für Ägypten (als politischem Schwergewicht im nahen Osten und zugleich wichtigem Reiseland) mit Abstand am größten ist. Ägypten stellt damit den 100%-Wert, an dem alle anderen Messwerte relativiert werden. Unter dieser Voraussetzung ist die tunesische Revolutions-Zacke noch einigermaßen erkennbar, für Syrien scheint die Kurve aber kaum noch sichtbar auszuschlagen. Dies ist natürlich einerseits eine Folge der Maßstabsveränderung, die durch den Vergleich mit dem Maximalwert für Ägypten entsteht (ein Phänomen das man beim Interpretieren unbedingt kennen muss). Andererseits spiegeln die Verhältnisse aber durchaus wieder, wie sich das Interesse der Öffentlichkeit über die Zeit hinweg entwickelt und verteilt. Syrien ist – verglichen mit Ägypten – eben „kein Thema“. Das Regime in Damaskus verhindert also einigermaßen erfolgreich, dass sich die syrische Revolutionsbewegung eindringlich im Bewußtsein der Deutschen zu verankert.
Exkurs: Die Mehrdeutigkeit von KPIs
Die Häufigkeit, mit der ein Begriff gesucht wird, ist auf den ersten Blick ein guter Key-Performance-Idikator oder „KPI“ für die Popularität eines Begriffs. Ob Populariät nun auch wünschenswert (also unter allen Umständen zu maximieren) ist, hängt wiederum von den Umständen ab. In vielen Fällen wird man z.B. für Markennamen wünschen, dass sie möglichst weit verbreitet sind. Setzt man voraus, dass die Eingabe eines Markennamens ein Indikator für „Interest“ (um den von Google selbst bezeichneten Begriff zu verwenden) ist, wäre ein hoher SVI-2 Index also wünschenswert.
Gänzlich anders verhält es sich jedoch, wenn die Popularität durch eine Negativmeldung verursacht wird. Ein Beispiel hierfür ist der Fall ist der des Fahrradschloss-Herstellers „Kryptonite“ dem im Jahr 2004 ein arger Fehler unterlaufen war. Die martialischen „Evolution 2000“ Stahl-Bügelschlösser konnten nämlich mit Hilfe der Hülle einer simplen Kugelschreiberhülle geknackt werden – ein Sachverhalt, der sich auf Youtube rasch herumsprach. Binnen kurzer Zeit kursierten einschlägige Videos von Kunden, die sich mit dem Knacken von Kryptonite-Schlössern munter die Zeit vertrieben. Und diese führten jedem potentiellen Kunden klar vor Augen, was ein Fahrraddieb wohl mit dem geliebten Zweirad machen würde, käme man auf die Idee, es mit einem „Evolution 2000“ von Kryptonite zu sichern. Die Popularitätskurve der Kryptonite Fahrradschlösser während dieser Zeit zeigt die folgende Abbildung:

Abbildung 7: Die Popularität des Suchbegriffs „kryptonite locks“ in den USA um den September/Oktober 2004 (Abbildung durch Anklicken vergrößerbar).
Man erkennt sehr schön, wie sich das, was unter dem Begriff „Lock Picking Fiasko“ bekannt wurde, in der Popularität des Suchbegriffs „Kryptonite Locks“ abbildet.
Die Kryptonite-Geschichte u.a. deshalb so oft und gerne als Beispiel für negative Publicity durch das Web zitiert, weil Kryptonite in einem PR-Reflex zunächst einfach abgestritten hatte, dass es mit seinen Produkten irgendwelche Probleme gebe… Die daraufhin durchs Social Web schwappende Welle der Empörung machte dann sogar die New York Times auf die Affäre aufmerksam – und führte so zu dem in der Abbildung oben zu sehenden, wahrhaft durchschlagenden Popularitätsgewinn. Angesichts der 10 Millionen Dollar Verlust, die das Unternehmen in diesem Zusammenhang gemacht hat, wäre es hier allerdings eher ironisch, von hoher Popularität als „Indikator für Erfolg“ zu sprechen. Trivial? Zugegeben. Wenn man es einmal weiß, ist vieles trivial. Andererseits können wir sicher sein: Der unbedarfte Betrachter neigt bei Variablen wie Visits, Page Impressions, Mentions in Sozialen Netzwerken, der Anzahl von Kommentaren oder der durchschnittlichen Betrachtungsdauer einer Seite usw. sehr leicht dazu, sie allesamt ziemlich einfach und eindimensional zu interpretieren: Viel hilft viel! Gut sind demnach viele PIs, viele Besucher und eine lange Betrachtungsdauer… Aber nein! Das stimmt eben nicht! Es kommt ganz klar darauf an, was da aus welchen Motiven und in welchen Situationen abgerufen, betrachtet, gelesen und bedient wird.
- Wird eine Seite nur kurz betrachtet, kann das bei einer mehrschrittigen Web-Anwendung ein gutes Zeichen sein: Die User verstehen, was sie tun sollen: Er oder sie füllt aus, Klick – und weg. Hier gilt: je kürzer, desto besser.
- Auf einem Corporate Blog ist das Umgekehrte, nämlich eine lange Betrachtungszeit als positiv zu werten. Der/die Besucher/innen lesen den Text wirklich? Gut. Das kostet Zeit und treibt die durchschnittliche Betrachtungsdauer nach oben.
Auch für DIE Erfolgswährung im Web, die Seitenaufrufe, finden sich analoge Beispiele:
- Wird eine Produktseite häufig aufgerufen, kann dies andererseits mit ziemlicher Sicherheit als Interesse am Produkt, also positiv gewertet werden.
- Häufige Seitenaufrufe einer Sitemap sind allerdings nicht unbedingt ein Zeichen dafür, dass sie ein „Top-Content“ ist und besonders gut funktioniert. Sie können auch so gewertet werden, dass die Besucher auf konventionellen Wegen nicht finden, was sie suchen und deshalb aus Verzweiflung auf die Sitemap ausweichen.
Wirft man alle Typen von Seiten und Content durcheinander, kommen also am Ende keine sonderlich aussagefähigen Indikatoren heraus. Web-Analytics Systeme unterscheiden aber leider nicht zwischen Seiten, bei denen eher eine kurze und solchen, bei denen eine lange Betrachtungszeit wünschenswert ist. Das können sie auch gar nicht, weil diese Entscheidung nur vom Verstand eines Menschen getroffen werden kann.
Zusammenfassend hoffe ich, dass unser kleiner Exkurs etwas von der Komplexität, aufzeigt, mit der wir konfrontiert sind, wenn Zahlen, die irgend ein Reporting-System in hübschen Grafiken ausliefert, wissenschaftlich interpretiert werden sollen. Hierzu passt in gewisser Weise, dass die Autoren hinter Google Insights for Search selbst darauf hinweisen, dass die Daten des Tools nicht für „harte“ wissenschaftliche Zwecke wie eine Doktorabeit oder ähnliches geeignet seien. Behält man dies im Hinterkopf kann das Tool jedoch sehr gut eingesetzt werden, um z.B. Popularität zu messen. Die Kurven können auch – dies zeigt das Beispiel „Kryptonite“ – als durchaus beeindruckendes Stilmittes der visuellen Rhetorik eingesetzt werden.
Mit der Auswertung der Trefferlisten der Google Suche lassen sich so allerlei erbauliche anthropologische Betrachtungen anstellen. In vielen launigen Glossen und Presseartikeln wird deshalb Bezug darauf genommen, ob und wenn ja welche Varianten von Wörtern oder Suchbegriffen in welcher Häufigkeit und Schreibwese verschieden lange Trefferlisten erzeugen – oder möglicherweise gar nicht zu finden sind. Das Ergebnis wird dann gerne essayistisch verwertet, um zu belegen, dass bestimmte Dinge so und nicht so und andere so herum aber nicht anders herum in den Köpfen des Suchmaschinen nutzenden Teils der Menschheit herumspuken. Dahinter steht die Prämisse, dass das, was in den den Suchschlitz der größten Suchmaschine der Welt eingetippt wird, eine Art Essenz oder Konzentrat der Wünsche und Gedanken der Menschheit sein müsse.
Gänzlich unrealistisch ist das nicht, denn natürlich suchen wir beim Surfen im Web Dinge,…
- …die für uns relevant sind,
- die wir uns wünschen,
- die uns betroffen machen,
- an die wir heimlich denken,
- für die wir uns interessieren.
Umgekehrt suchen wir niemals nach etwas, das wir nicht kennen und nur sehr selten nach Dingen, die uns herzlich gleichgültig sind. Insofern ist aus der Sicht eines Marktforschers eine Statistik von Sucheingaben (sei es auf der eigenen Website oder „off site“ auf einer großen Suchmaschine) eine ziemlich interessante Informationsquelle.
Ich möchte deshalb in diesem und einem noch folgenden Beitrag über Auswertungen und Kennzahlen berichten, die über „Google Trends“ (http://trends.google.com) und „Google Insights for Search“ (http://www.google.com/insights/search), erzeugt werden können. Ich hoffe, es gelingt mir zu zeigen, dass man mit diesen Tools (und etwas Geduld, Phantasie und Systematik) einige durchaus interessante und ziemlich direkte Blicke in die Köpfe der Internet-Gemeinde werfen kann.
Google Trends:
Das Szenario:
Beginnen wir mit einem gar nicht so unrealistischen Szenario: Die Redaktion der monatlich erscheinenden Frauenzeitschrift mit dem ebenso einfallsreichen wie zutreffenden Titel „Frau“ hat einen rasend spannenden Artikel über eine neue Diät auf Halde, der in Kürze erscheinen soll. In der Redaktionskonferenz kommt die Frage auf, ob das Interesse an dem Thema „Diäten“ und „Abnehmen“ am geplanten Erscheinungstermin (November 2011) möglicherweise jahreszeitbedingt erhöht oder verringert sein könnte. Hier kann man interessanterweise ganz unterschiedliche Vorhersagen ableiten.
Die Gier-Hypothese:
Einige Redaktionsmitglieder vertreten die Ansicht, der Spätherbst sei sehr gut geeignet, weil in der dunklen Jahreszeit die Gier auf Kalorien ja zunehme und die Leserinnenschaft insofern besonders an Tipps interessiert sein müsse, wie man diese im Zaum halten könne. Aus diesem Grund sei das Thema im Novemberheft von „Frau“ gut platziert. Headlines wie „Bleib schlank im Herbst“ oder „Der Diät-Workout für die Festtage!“ machen schon die Runde.
Die Verdrängungshypothese:
Eine zweite Fraktion meint, das genaue Gegenteil müsse der Fall sein: November, das sei doch die Zeit von Spekulatius, Stollen und anderer vorweihnachtlicher Leckereien! Da sei niemand ernstlich an einer Diät als Spaßbremse interessiert. Vielleicht könne man aber nach den Festtagen, wenn der erste Kontakt mit der Waage die Folgen der Völlerei unmissverständlich deutlich macht (und obendrein die Zeit der guten Vorsätze fürs nächste Jahr anbricht), ein gesteigertes Interesse am Thema Abnehmen und Diät verzeichnen. Der Beitrag müsse also in das Januarheft, ganz klar.
Eigentlich sind beide Hypothesen plausibel, oder? Ja. Möglicherweise heben sich die Effekt auch gegenseitig auf? Ohne weitere Daten lässt sich dies nicht klären, da kann nur das Machtwort der Chefredakteurin entscheiden. …ob die unfehlbar ist? Sie selbst wäre dieser Hypothese nicht abgeneigt, aber bevor sie nun die Trumpfkarte spielt, als mächtigste und am besten bezahlte Person in der Runde die Wahrheit definieren zu können, bringen wir unsere Suchmaschinen-Tools in Stellung.
Wie man Google Trends benutzt:
Mit „Google Trends“ können wir die im Raum stehende Frage nämlich klären. Hierzu bedarf es zweier Vorannahmen, dass nämlich (a) die Suche nach dem Begriff „diät“ auf Google in Zeitperioden mit einem hohen/geringen Interesse an Diäten zu/abnimmt, und (b) dass dieser Effekt so deutlich ist, dass er von der zweiten Bedeutung des Wortes (der „Diäten“ von Abgeordneten) nicht übermäßig kontaminiert wird. Der Rest ist denkbar einfach: Man ruft die Seite http://trends.google.com auf und tippt das Suchwort, für das man sich interessiert, in das Eingabefeld. Auf der folgenden Seite kann man dann die Suche weiter eingrenzen, indem man eine Region und einen Zeitraum für die Abfrage spezifiziert. Sucht man nach der Häufigkeit des Wortes „diät“ im Google Search Volume für „Deutschland“ innerhalb der „letzten 12 Monate“ vor dem Erscheinungsdatum dieses Artikels (Juni 2011), erhält man folgende Grafik:

Was können wir schlussfolgern?
Wenn die blaue Linie die Häufigkeit der Suchanfragen für „diät“ wiedergibt (was die Zahlen genau bedeuten, werden wir gleich noch sehen), scheint es um die Jahreswende einen bemerkenswerten Effekt zu geben. Ab Mitte November sinkt die Kurve deutlich ab, um genau nach Weihnachten schlagartig anzusteigen. Das entspricht auf den ersten Blick natürlich sehr deutlich der Verdrängungshypothese (s.o.). Und den optimalen Zeitpunkt für einen Artikel zum Abnehmen haben wir genau lokalisiert: Es ist der 1. Januar. Dort vermischen sich vermutlich die Schuldgefühle wegen der angefutterten Pfunde mit den guten Vorsätzen fürs neue Jahr. Also: Die Verdrängungshypothese hat gewonnen, die Chefredakteurin kann ihre Autorität und Erfahrung für sich behalten. Und wir haben nicht nur gesehen, wie man Google Trends als Messinstrument einsetzt, wir können auch einen Namen für einen Effekt aus der Taufe heben – ein Brauchtum, dem in der Wissenschaft immer wieder gerne nachgegangen wird. Also: wir haben Dr. Wirths „Jahresend-Diät-Zacke“ gefunden!
Die Berechnung des „Search Volume Index“:
Bis jetzt habe ich eine Frage unterschlagen, die einigen meiner Leserinnen und Leser wahrscheinlich auf der Zunge liegt und/oder den Nägeln brennt: Was bedeuten eigentlich die Werte auf der y-Achse der Grafik, die mit „Search Volume Index“ überschrieben sind? Die einfachste Antwort ist zunächst – wie immer in solchen Fällen – die Formel, mit der die Werte bestimmt werden:

Formel 1: der Search Volume Index als Formel (Erläuterungen im Text)
Zur Erklärung: Der SVI errechnet sich immer für einen bestimmten Tag relativ zu der vom Benutzer vorgegebenen Zeitperiode. Die mittlere Häufigkeit des Suchworts während dieses gesamten Zeitraums steht also im Nenner des Bruchs, im Zähler steht die beobachtete Häufigkeit an dem Tag, für den der Index gerade bestimmt wird. Klingt vielleicht etwas verwirrend, ist aber ganz einfach, wie man an einem Berechnungsbeispiel zeigen kann: Nehmen wir an, in den vergangenen 12 Monaten wurde das Wort „diät“ im Durchschnitt 500 mal am Tag gesucht, und am 1. Mai waren 50 Suchanfragen zu verzeichnen. Dann berechnet sich der Search Volume Index (SVI) für den 1. Mai folgendermaßen:

Formel 2: Berechnungsbeispiel für den SVI (Erläuterungen im Text)
Man erkennt, dass es eine gewisse Verwandtschaft zwischen dem SVI und der Prozentrechnung gibt. Tatsächlich können die SVI-Werte durch eine einfache Multiplikation mit 100 in Prozente umgerechnet werden.
- SVI = 0,5 besagt, dass das Wort an dem betreffenden Tag halb so oft (50%) gesucht wurde wie im Durchschnitt der angegebenen Periode,
- SVI = 3,0 besagt, dass das Wort 3 mal so häufig (300%) gesucht wurde.
- SVI = 1,2 besagt, dass die Häufigkeit der Suchanfragen für das Wort 20% erhöht (also 120%) war.
- usw.
Ein SVI von beispielsweise 0,5 kommt also bei einem Verhältnis der Anfragen am Zieldatum zu Anfragen in der Periode von 2.000 : 1.000 oder 100 : 50 oder 40 : 20 oder gar 2 : 1 zustande.
Es geht hier also immer nur um die relative Verteilung der Anfragen in dem vorbestimmten Zeitraum. Die absolute Zahl der Suchanfragen lässt sich mit dem Search Volume Index nicht bestimmen!
Linguistische Probleme (Pardon: Herausforderungen)
Das Problem bei der Verwendung des Search Volume Index ist natürlich, dass Wörter oder Zeichenketten mehrere Bedeutungen haben können. Gar nicht so selten gibt es z.B. für Wörter im Deutschen englische Zwillinge mit gleicher Schreibweise aber völlig unterschiedlicher Bedeutung. Das deutsche Wort „Fasten“ eignet sich für unsere kleine Studie zum Thema Abnehmen im Jahresverlauf beispielsweise nicht gut, weil man im Englischen „von Fasten Seatbelts“ spricht, wenn Sicherheitsgurte angelegt werden sollen. Diese Fälle würden also fälschlicherweise zu unserem Suchindex addiert. Eine Sprachwahl für die Suchbegriffe bietet die Benutzeroberfläche von Google Trends aber leider nicht an. Immerhin kann man aber die üblichen Google-Suchoperatoren verwenden, d.h. kann man durch Voranstellen eines Minus-Zeichens eine bekannte englische Bedeutung aus dem Suchstring ausschließen. Die Anfrage wäre dann: „fasten -seatbelts“.
Aber auch im Deutschen gibt es Wörter, die je nach Verwendungskontext bei gleicher Schreibweise in unterschiedlichen Bedeutungen verwendet werden. So ist es auch bei unserem Beispiel: Kann der Effekt in Abbildung 1 auf ein saisonales Interesse an „Abgeordneten-Diäten“ zurückgehen? Wir können das nicht direkt prüfen. Allerdings können wir in Google Trends ein zweites oder drittes, insgesamt bis zu 5 Suchwörter heranziehen und ihre relative Häufigkeiten im Zeitverlauf sichtbar machen. Um unsere Interpretation in Sachen Diät abzusichern, bietet sich als Vergleichsobjekt ein Wort an, das dem Begriff „diät“ ähnlich, aber sicher nicht auf Abgeordnetendiäten bezogen ist. Dies ist z.B. das Wort „abnehmen“. Die folgende Abbildung zeigt das Ergebnis einer vergleichenden Abfrage der Begriffe „diät“ und „abnehmen“, wiederum über die letzten 12 Monate, wiederum in Deutschland.

Abbildung 2: Häufigkeiten für Suchanfragen nach "diät" und "abnehmen" - fällt Ihnen etwas auf?
Gut. Nun wissen wir, dass es wirklich die Diäten im Sinn von Gewichtsreduzierung und nicht die Abgeordnetendiäten sind, welche die charakteristische Zacke am Jahreswechsel erzeugen. Anders wäre die auffällige Parallelität im Verlauf der Kurven nicht zu erklären. Wir können die Verdrängungshypothese also beibehalten. Und anscheinend ist der jahreszeitlich bedingte Wechsel von Unaufmerksamkeit (ab Mitte November) und erhöhter Aufmerksamkeit (etwa ab Weihnachten) für Themen rund um das Thema Gewichtsreduzierung bei dem Begriff „abnehmen“ sogar noch markanter.
Man erkennt an Abbildung 2 übrigens, dass der Begriff „abnehmen“ gemessen an der Häufigkeit des Begriffs „diät“ insgesamt um einen Faktor 1.64 häufiger ist (vgl. die Legende für die beiden Kurven). Auf 100 „diät“-Anfragen kommen also im Durchschnitt 164 „abnehmen“-Anfragen. Dies ist ein Grundprinzip der Google Trends Auswertung: Die durchschnittliche Zahl von Suchanfragen für die gewählte Zeitperiode wird für den ersten Begriff, den man eingibt = 1 gesetzt, und alle weiteren Werte und Kurven werden an dieser Norm gemessen.
Die relative Häufigkeit des Auftretens mehrerer unabhängiger Suchbegriffe über die Zeit kann also mit Hilfe des SVI verglichen und analysiert werden.
Spezielle Auswertungen
Die Schuldfrage
Wie verblüffend einfach und direkt sich mit mit dem SVI bestimmte Bedeutungszusammenhänge des alltäglichen Lebens darstellen lassen, zeigt die folgende Grafik. Sie setzt den Verläufe des SVI für die Begriffe „abnehmen“ und „gänsebraten“ zueinander in Beziehung.

Abbildung 3: Verlauf der Suchanfragen für "abnehmen" und '"gänsebraten - fällt Ihnen etwas auf?
Man erkennt leicht: Das Interesse für Gänsebraten steigt ab Oktober allmählich in einem flachen Gradienten an (wo ist das beste Rezept….?), zeigt eine markante Zacke um die Weihnachtszeit und fällt dann ebenso rasch wieder unter ein messbares Niveau. Es verhält sich also exakt umgekehrt zum Interesse für „abnehmen“ – wen wundert‘s? Wer Rezepte für den Weihnachtsbraten recherchiert, hat eben nicht die richtige mentale Einstellung fürs Kampf-Fasten. Wenn die Reste verdaut sind, erwacht mit dem schlechten Gewissen das Interesse für Diäten erneut und die „Jahresend-Diät-Zacke“ wird sichtbar.
Die Kulturfrage
Mit dem letzten Auswertungsbeispiel greife ich dem zweiten Artikel dieser Serie, in dem es in Kürze um „Google Insights for Search“ gehen wird, etwas vor. Es ist jedoch noch einmal gut geeignet, die Daten, die man aus Google Trends gewinnen kann, zu „validieren“, sprich: ihre Gültigkeit als Messwert nachzuweisen. Hierzu folgende Überlegung: Wie mag das Interesse für Diäten und Abnehmen in Ländern entwickeln, die keine christlich-weihnachtliche Fresstradition haben? Also zum Beispiel in muslimischen oder buddhistischen Ländern? Hier dürfte es – nach allem, was mein gesunder Menschenverstand mir sagt ., keine Jahresenddiätenzacke geben. Das Phänomen ist rein logisch an das Vorhandensein eines hohen Feiertags mit Fressritual und Vorglühphase gebunden. Fehlt das Ritual, müsste das Interesse an Diäten einigermaßen konstant sein. Können wir das nachweisen…?
Der Test steht und fällt mit einem geeigneten Vergleichsfall. Wir brauchen hierfür ein Land, das folgende Bedingungen erfüllen muss:
- Englisch muss Verkehrssprache sein, oder es ist mindestens mit einem signifikanten Anteil englischsprachiger Suchanfragen zu rechnen. Sofern Englisch nicht in Frage kommt ist alternativ leicht zu recherhieren, was „diät“ in der Landessprache heißt.
- Es sollten möglichst keine speziellen Zeichensätze zu installieren sein, um die Anfrage machen zu können (damit entfällt z.B. Japanisch, Arabisch und Chinesisch). Dies ist kein logisch zwingendes, sondern ein rein pragmatisches Argument.
- Die Kultur muss in weiterem Sinn nicht-westlich geprägt, also einer anderen Weltreligion zugehörig oder (wie in den wenigen verbliebenen sozialistischen Ländern der Erde) „atheistisch“ orientiert sein.
Nach einigen Recherchen und Versuchen habe ich mich für Indonesien als Region mit Englisch als Zweit-Sprache und einer eher asiatisch-chinesisch geprägten Kultur entschieden. Sicherlich gibt es auch Europäer in Indonesien, doch wenn die Hypothese stimmt, dass Google Trends die Denkwelten widerspiegelt, die in der Bevölkerung einer Region vorherrschend sind, dann sollte die Jahresenddiätenzacke hier entweder fehlen oder mindestens deutlich weniger prägnant ausgeprägt sein. Das Ergebnis der Abfrage „diet“ für Indonesien in den vergangenen 12 Monaten zeigt die folgende Abbildung:

Abbildung 3: Verlauf des Interesses für "diet" in der Region Indonesien - fällt Ihnen etwas auf?
Man sieht: die Jahresend-Diät-Zacke ist kaum zu sehen, sie geht in den natürlichen Schwankungen der Zeitreihe unter. Also: Das Ergebnis spricht für die Validität des Search Volume Index als Indikator für das Interesse an einem Thema in einer Kultur, mindestens unter bestimmten Umständen.
Zwischenbilanz und Ausblick
Hat man das Prinzip des SVI einmal verstanden, gibt es eigentlich nur noch drei Dinge, die dem Einsatz dieses kleinen Spielzeugs Grenzen setzen:
- Das Erste ist natürlich wie immer die Phantasie des Benutzers: Welche Sucheingaben relevant? Welche sind interessant? Welche sind aussagefähig? Mit welchen kann man Einsichten in das Informationsverhalten des Publikums gewinnen? Welche sind trivial und zeigen, was wir ohnehin alle wissen? Welche können einen notwendigen Nachweis für eine allseits geteilte und geglaubte aber möglicherweise fehlgeleitete Überzeugung liefern?
- Das Zweite ist die sprachliche Präzision: Welche Begriffe kann man ausreichend eindeutig formulieren? Welches sind überhaupt die richtigen, trennscharfen Begriffe für ein Thema? Gibt es eventuell mehrere, gleichwertige Suchwörter für ein Thema? Welches ist dann zu wählen? In welchen Kulturen und Sprachen kann man sich überhaupt mit einiger Sicherheit bewegen?
- Das Dritte ist die Häufigkeit der Suchbegriffe: Diese spielt eine sehr direkte Rolle für die Verwendungsmöglichkeiten des Instruments. Google gibt hierzu keine genauen Informationen – soweit ich es recherchieren konnte – aber es gilt die Faustregel: Seltene Suchanfragen erzeugen leere Seiten und ein dummes Gesicht. Special Interest Recherchen sind also nicht möglich. Damit entfällt auch die Möglichkeit, kulturvergleichende Messungen in kleinen Regionen zu machen.
Trotz der Fragezeichen kann Google Trends interessante Zusatzinformationen für Forschungsfragestellungen liefern. Im nächsten Beitrag werde ich mich mit dem ähnlich arbeitenden aber deutlich vielseitigeren Tool „Google Insights for Search“ beschäftigen und dessen Nutzen für die Messung von Markenimage und Reichweiten von Kommunikation genauer unter die Lupe nehmen. Dieses Tool ist im Unterschied zu Google Trends nur zu verwenden, wenn man ein Google Konto hat. Allerdings: wenn man in den sauren Apfel beißt und sich bei der größten Datenkrake der Welt vielleicht notfalls unter einem Pseudonym registriert und einloggt, hat man ungeahnte Möglichkeiten, das Suchverhalten der Internet-Gemeinde weltweit zu untersuchen.
„Wabi-Sabi“ ist ein Begriff aus dem traditionellen Japanischen (übrigens nicht zu verwechseln mit dem fast gleichnamigen Wasabi-Meerrettich), der eine bestimmte Eigenschaft von Objekten beschreibt, für die es – bezeichnenderweise – keine direkte Übersetzung im Deutschen gibt. Man könnte vielleicht sperrige Begriffe wie „Gebrauchsrobustheit“ oder „Materialangemessenheit“ erfinden, diese mit „Schönheit“, „Stil“ und „Dauerhaftigkeit“ vermischen, und hätte dann möglicherweise annähernd ausgedrückt, worum es geht. Aber gerade deshalb, weil es in westlichen Kulturen kein sprachliches Äquivalent zu Wabi-Sabi“ gibt, ist der Begriff so interessant.
In der Wab-Sabi Philosophie der Gestaltung werden die Kunst, künstlerisches Handwerk, Qualität und Schönheit auf eine ganz eigene Art betrachtet. Ich möchte nun nicht die Illusion wecken, ich könnte diese in einigen Sätzen so erklären, dass ein japanischer Kalligraph, Töpfer oder Maler damit zufrieden wäre. Ein wichtiger Gedanke des Wabi Sabi ist mir jedoch sehr eingängig: Künstler, Gestalter, Designer (oder die jeweiligen -innen) sollten den späteren Gebrauch eines Objekts bei seinem Entwurf vorwegnehmen. Es soll also nicht nur berücksichtigt werden, wie etwas gut funktioniert. Genauso wichtig ist, wie Materialien altern, und ebenso, wo und wie sich Abnutzung auf Formen, Farben und Oberflächen auswirkt.
Eine gute Idee
Natürlich ist es sinnvoll, zu überlegen, welche Veränderungen mit einem Gegenstand vor sich gehen werden, der für lange Zeit in Gebrauch sein wird. Der Zustand der Neuheit ist ja buchstäblich nur ein Augenblick: kurz, sehr rasch vorüber und obendrein kaum wiederholbar. Die bei weitem überwiegende Mehrheit der Objekte, die uns in unserem Alltag umgeben, sind deshalb mehr oder weniger alt, mindestens Monate, zum Teil Jahre oder gar Jahrzehnte. Hierfür – für das Altern und Benutzt werden – sollten sie dann auch gedacht und gemacht werden. Eine Gestaltung im Geiste von Wabi-Sabi verschiebt ästhetische Idealvorstellungen Richtung auf asymmetrische, ungleichmäßige, organisch wirkende Formen, rauhe und gemaserte, unregelmäßige Oberlächen, denn diese widerstehen der Zeit am besten. Ein weiterer Gedanke, des Wabi Sabi: Dinge sollten möglichst NICHT PERFEKT sein. Makel, z.B. eine kleine Abweichung von der Idealform, eine Verfärbung, eine Narbe, Unregelmäßigkeiten in der Maserung usw. werden also nicht vermieden und im schlimmsten Fall als Ausschuss klassifiziert und entsorgt. Nein, sie werden ganz im Gegenteil regelrecht eingeplant – wobei man vielleicht richtiger sagen sollte, dass es sich um planvoll Ungeplantes handelt, denn jede systematisch, präzise ausgeführte Unregelmäßigkeit würde den Grundgedanken des Wabi Sabi ad absurdum führen. Dieser Ausschnitt eines alten Tisches verdeutlicht exemplarisch, wie eine Oberfläche aussieht, die dem Wabi-Sabi Prinzip folgt:

- Wabi-Sabi Fundstück: Die Oberfläche meines Küchentischs

Gut und schön ist nur, was NEU ist?
Analysiert man nun unsere westliche Produktwelt etwas kritischer, erkennt man ohne viel Mühe, dass die einfachen und fast trivial anmutenden Forderungen nach Langlebigkeit und funktioneller Gestaltung im Sinn von Wabi-Sabi sehr oft ausdrücklich NICHT berücksichtigt werden. Ganz im Gegenteil: viele moderne Gegenstände und Produkte sind NUR im perfekten Neuzustand, möglicherweise sogar nur in ihrer Verpackung, wirklich „richtig schön“. Sobald die Zeit oder der Gebrauch die ersten Spuren hinterlassen, geht es rapide bergab. Das gilt für Spielzeuge, Möbel, Kleidung, Autos, Uhren, Schuhe, Computer, Elektrogeräte, Geschirr und und und. Anschaulichstes Beispiel ist vielleicht der allererste Kratzer im Lack eines neuen Autos, der bei der Besitzerin oder dem Besitzer in der Regel eine Mischung aus Erschrecken, Melancholie und Bestürzung auslöst – natürlich gepaart mit einer sich auf den Verursacher des vermaledeiten Kratzers gerichteten Wut. Meine Güte, das schöne Auto! Der redensartlich abblätternde Lack ist dann ja auch eine oft und gern gebrauchte abfällige Formulierung, die sich dieses eherne Gesetz unserer westlichen Zivilisation ganz direkt zunutze macht, eben: Gut und schön ist nur, was NEU ist!
Fetische der Digital Natives…
Man könnte hinzufügen: nicht nur neu, sondern auch makellos, ebenmäßig, symmetrisch, glatt, faltenlos, glänzend, spiegelnd, sauber… Und das ist natürlich irgendwie kompletter Unsinn, denn die Welt hat Makel, und deshalb ist mit makellosen Dingen nicht gut auszukommen. Die vielleicht extremsten Beispiele für diesen Wahn der Neuheit und Unversehrtheit, sind die Produkte der kalifornischen Firma Apple, die ja innerhalb der vergangenen Dekade den ersten Platz als eine Art kollektivneidauslösendes Statussymbol erobern und sich zu Ikonen des Designs, regelrechten Fetischen entwickeln konnten. Hiervon zeugt u.a. der der rennommierte „Red Dot Design Award“, den das Apple Design Team im Jahr 2002 gewinnen konnte. In der Tat: Sollte irgendeine Ausstellung in ferner Zukunft den gestalterischen Zeitgeist des beginnenden 21. Jahrhunderts anhand beispielhafter Exponate darstellen wollen, die Palette der „Mac“- und „i“-mit-Irgendwas-Produkte wäre mit Sicherheit vertreten.
…mit gewissen Schwächen
Eine solche Ausstellung wäre allerdings nur vollständig, wenn ergänzend zu den glattpolierten Primär-Fetischen auch die breite Palette der sekundären Schon- und Schutzhüllen sowie produktbezogenes Reparaturequipment und Prothesen gezeigt würden. Allesamt Dinge, die für sich genommen überhaupt keinen Sinn machen, die man sich aber fast notwendig kaufen muss, um zu verhindern, dass das eigentlich interessierende Objekt irgendwelchen schädlichen Umwelteinflüssen ausgesetzt wird. „Schädlich“ ist dabei eigentlich alles, was in irgendeiner Form auf die Oberfläche des
Geräts einwirkt. Deshalb darf man beispielsweise auf gar keinen Fall iPods, iPhones oder iPads ungeschützt der feindseligen Atmophäre eines Rucksacks oder einer Tasche aussetzen! Die Oberfläche der Displays der iPod-Generationen, die sich um das Jahr 2005 anschickten, den Weltmarkt zu erobern, war derart empfindlich gegen Kratzer, dass sie bei ungeschützter Aufbewahrung ohne eine geeignete Hülle binnen Tagen völlig verschrammt und hässlich wurde. (Man kann entsprechende Blog- und Foren-Einträge ohne Mühe im Dutzend finden). Mittlerweile haben die Kunden gelernt, dass mindestens eine Schutzhülle (z.B. aus einem derart coolen Material wie „thermoplastischem Polyurethan“) zur notwendigen Standardbewaffnung jedes iPod- oder sonstigen i-Dings-Trägers (bzw. -Trägerin) gehört.
Kundenerfahrung(en)
Meine eigenen Erfahrungen mit dem besonderen Charme der makellosen Produkte mit dem Apfel-Logo reichen zurück in die Zeit, als mir ich den ersten iPod (ein iPod Nano, silbern, mit 8 GB Speicher) anschaffte. Die wie ein Präzisionsspiegel polierte Rückseite dieses Gerätchens ertrug einfach keine Berührung. Jeder Kontakt mit menschlicher Haut bewirkte eine sofortige partielle Erblindung der Oberfläche, die beim Besitzer des Geräts (also mir) augenblicklich eine Hauch-, Fummel-, Reinigungs- und Polier-Attacke auslöste, die dann anhielt, bis das Ding wieder ebenso ordnungsgemäß wie makellos spiegelte. Der Kauf eines geeigneten Etuis, das die übereifrig glänzende Oberfläche gnädig mit ziemlich hässlichem aber unempfindlichem Kunstleder bedeckte, ließ nicht lange auf sich warten… Allerdings hat sich mir schon damals die Frage gestellt, wozu man eine solche Oberfläche überhaupt für ein Gehäuse verwendet, wenn sie so lebensuntüchtig ist, dass man sie ohnehin abdecken muss.

Hochglanzprodukte: Man beachte den garantiert verschmutzungsresistenten digitalen Spiegeleffekt. Quelle: amazon.de
Und ich bin und war beileibe nicht der einzige, der sich hier ärgerte. Wer sich ein wenig Zeit nimmt und recherchiert, findet im Web allenthalben und ohne Mühe Spuren des Kampfes der Kunden mit den hyperblanken, hochempfindlichen Oberflächen der Apple-Produkte. Ich empfehle Suchwortkombinationen wie „ipod kratzer display“ (155.000 Treffer bei Google).
Apokalypse in Schwarz
Der blanke Irrsinn tritt nun allerdings ein, wenn die schonenden, schützenden Hüllen ihrerseits so empfindlich gefertigt werden, dass man sie eigentlich mit Hüllen zweiter Ordnung verpacken müsste, um sich noch einigermaßen wohl fühlen zu können. Unübertroffen in dieser eigenartigen Disziplin ist die von der Firma Apple selbst als Zubehör für das iPad angebotene Original-Schutzhülle. Sie besteht nicht aus einem strapazierfähigen Material wie Leinen, Leder, Kunstleder (oder meinetwegen thermoplastischem Polyurethan), sondern aus einer moosgummiartigen Substanz, die – ganz konform mit der feschen Optik des eigentlichen Produkts – in samtigem Schwarz gehalten ist. Zu der Schutzhülle erhält der Kunde ein kleines schwarzes, sakral anmutendes Tüchlein, das sich anfühlt wie Rohseide. Haptik und Optik stimmen und passen ausgezeichnet zur Klavierlack-Anmutung des eigentlichen Geräts. Das Tüchlein dient der schonenden Politur des Touch-Screens des Geräts und ist angesichts dessen fingerabdruckkonservierender Empfindlichkeit wirklich praktisch. Eigenartig ist etwas anderes. Es fällt SOFORT auf, wenn man die Hülle ihrer Bestimmung gemäß in die Hände nimmt und zu benutzen beginnt. Das Material verzeiht nämlich keine Berührungen, und zwar ganz grundsätzlich nicht. Niemals und von Niemandem. Es ist auch nicht einfach blank zu wienern, wie das Objekt, zu denen Schonung und Schutz es eingesetzt wird, auch unser Schwarztüchlein versagt. Um meinen Leserinnen und Lesern einen Eindruck davon zu geben, wie sie sich verhält, habe ich die Hülle fotografiert und einen kleinen aber repräsentativen Ausschnitt der Oberfläche hier dargestellt.

Ein buchstäblicher Schmutzfänger: Die Oberfläche der Apple iPad Hülle
Ich möchte betonen, dass der abgebildete Zustand das Ergebnis einer normalen Benutzung des Geräts ist. Ich habe nichts beschönigt und nichts zusätzlich getan, um das Aussehen der Oberfläche zu verändern. Ich habe mich auch vor der Benutzung nicht im Staub gewälzt.
Das Bild kommentiert sich selbst.
Ursachenforschung
Wie konnte es dazu kommen, dass ein Gigant, eine Weltfirma wie Apple einen solchen rohrkrepierenden Autoimmundefekt von einer Hülle produziert und zu Tausenden verkauft? Warum leiden die Produktpaletten des Unternehmens nahezu vollständig unter diesen eigenartigen Empfindlichkeiten? Ich weiß es nicht mit Sicherheit zu sagen, kann aber einige Hypothesen beisteuern. Ich vermute, es ist letztlich eine Kombination dieser Faktoren:
- Die erste: Es hat niemand etwas bemerkt. Die Produktmanager, Designer und Führungskräfte bei Apple Inc. einschließlich Steve Jobs sind nämlich allesamt Zwangsneurotiker, die sich durchschnittlich 132 mal am Tag die Hände waschen und regelmäßig durch Polieren glatter Oberflächen ihre Libido zum Qualmen bringen.
- Die zweite: Man hat bei Apple Inc. irgendwann den Unterschied zwischen Screen- und Produktdesign komplett verlernt. Deshalb versucht man die stylish-fancy-glossy Oberflächen, polierte Icons und Buttons aus den hauseigenen User Interface Styleguides in der Realität nachzubilden – ohne einen Gedanken darauf zu verschwenden, ob das überhaupt Sinn macht und welche Folgen dies hat.
- Die dritte: Man interessiert sich eigentlich gar nicht für langlebige Produkte, die ein Höchstmaß an Toleranz gegenüber jedem Umwelteinfluss erdulden und insbesondere ihre Benutzung klaglos hinnehmen. Stattdessen möchte man Produkte mit möglichst geringer Halbwertszeit herstellen, damit die Gier nach einem neuen, schönen makellosen, jungfräulichen Produkt möglichst rasch neu entfacht wird.
- Die vierte: Apple fällt mit schöner Regelmäßigkeit und großem Selbstbewußtsein seiner Glossy-Shiny-Pseudo-Klavierlack-Ästhetik zum Opfer und versteht überhaupt nichts von der Philosphie des Wabi-sabi.
Mehr Informationen zum Thema
Ich selbst bin eher zufällig durch eine Randbemerkung einer Künstlerin auf den Begriff Wabi-sabi aufmerksam geworden. Die Sache hörte sich aber so interessant an, dass ich zu recherchieren begann. Die beste Quelle, die mir hierbei untergekommen ist, ist ein Büchlein mit dem Titel „Wabi-sabi für Künstler, Architekten und Designer: Japans Philosophie der Bescheidenheit“, herausgegeben von Mathias Dietz, erschienen im Wasmuth Verlag. zum Titel bei Amazon
Der Schweizer Fotograf Andreas Hurni hat auf seine Website einen schönen Text zu Wabi sabi geschrieben, der auch vom Unterschied westlicher Ästhetik und japanischer / Zen-Ästhetik behandelt. zum Artikel.
